本文转载自微信公众号「后端研究所」,作者指南针氪金入口。转载本文请联系后端研究所公众号。
说个大事儿
各位吴彦祖&刘亦菲,大家好!
经过深入思考,本号主决定花1-2年时间强更一个系列,暂且叫它《面霸导论》吧!
《面霸导论》有几大块内容:
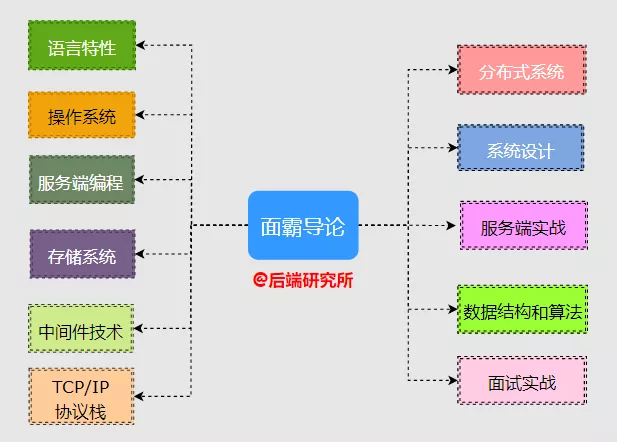
今天这篇是《面霸导论》第一弹,文章是需要反复琢磨的,今天先来搞一下进程调度。
嘟嘟嘟!抓紧上车了!
准备知识
想深入理解操作系统的进程调度,需要先获得一些准备知识,这样后面就不懵圈啦:
- 调度究竟是个啥
- 操作系统有哪几种?常用的是哪种?
- 进程的分类和优先级是怎么回事
- 抢占式调度和非抢占式调度有啥区别
- 如何设计一个可用的调度器
调度的概念
科技源自生活,调度系统绝对不是计算机领域的专利,现实生活中调度无处不在:
- 连锁超市某些热门商品短缺,就需要在全城范围内考虑人口密度、超市规模、商品缺口等多个因素,进行资源调配
- 铁路部门为了应对春运会在热门线路增加列车来缓解运输压力,春运结束则恢复正常
调度是为了解决资源和需求之间的不匹配问题,现实往往是资源少&需求多,计算机领域也是如此。
在操作系统中CPU资源是有限的,需要使用CPU的进程数量是不确定的,并且大部分情况下进程数量远大于CPU数量,如何解决不匹配问题就是进程调度核心:

操作系统
分类操作系统的种类非常多,本身上是硬件层和应用层之间的中间层,对上与应用程序进行交互,对下实现硬件资源的管理。
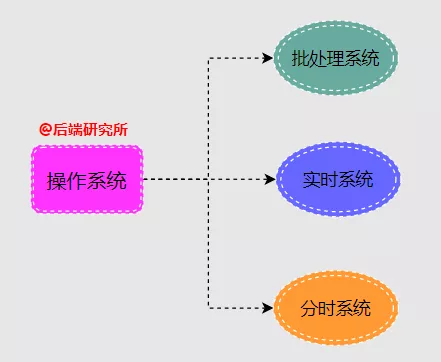
- 批处理系统( Batch Processing System )
批处理是指用户将一批作业提交给操作系统后就不再干预,由操作系统控制它们自动运行,这种采用批量处理作业任务的操作系统称为批处理操作系统,不具有交互性,用户无法干预任务的运行。
- 实时系统( Real-Time System)
实时系统最大的特点在于计算的正确性不仅取决于程序的逻辑正确性,也取决于结果产生的时间,如果系统的时间约束条件得不到满足,将会发生系统出错,强实时系统一般应用在航空航天、导弹导航制导、核工业等领域。
- 分时系统( Time Sharing System)
分时系统将计算机系统资源(比如CPU)进行时间上的分割,每个时间段称为一个时间片,每个用户依次轮流使用时间片,由于时间间隔很短,每个用户的感觉就像他独占计算机一样,从而有效增加资源的使用率,提高用户交互体验。
Linux属于分时系统,是互联网服务器的主流操作系统,重点研究它就行!
进程分类
根据进程运行时的状态,可以分为:
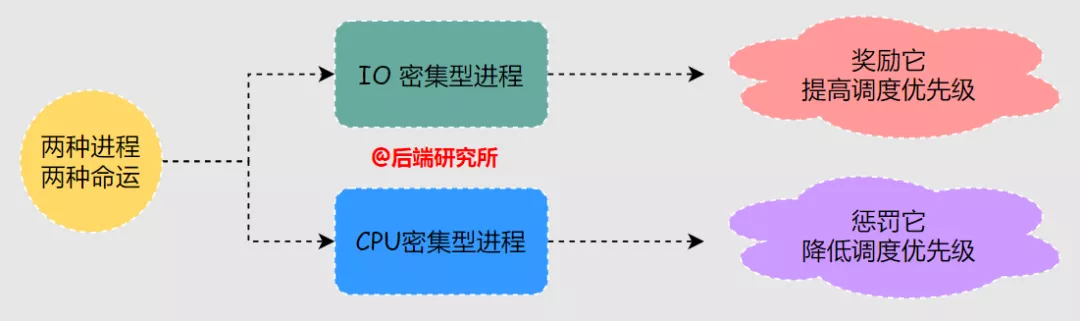
- I/O密集型( IO-bound )
在进程占用CPU期间频繁有IO操作,出现IO阻塞等待情况,比如负责监听socket的进程,真正使用CPU进行计算的时间并不多。
- CPU密集型( CPU-bound)
在进程占用CPU期间基本都在进行计算,很少进行IO操作,期间对CPU的真实使用率很高。
进程调度器需要根据进程是IO密集型还是CPU密集型会采用不同的策略。
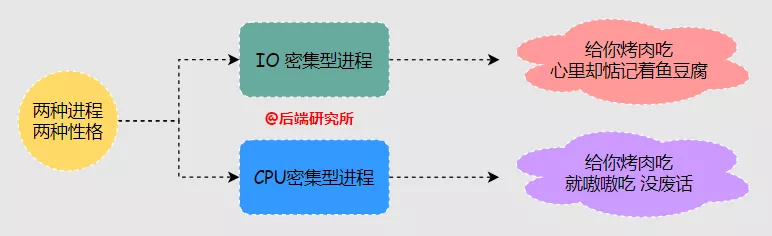
在调度器中往往需要对IO密集型进程进行奖励来提高其调度优先级,对CPU密集型进程进行惩罚降低其调度优先级。
对进程的奖惩策略是调度器的一项核心工作,希望大家务必理解:
交互进程往往伴随较多的IO操作,同时也是响应时间敏感的任务,鼠标点一下半天没响应,想想就很糟糕,因此属于高优先级进程。
非交互进程往往是纯CPU计算,用户是无感知的,所以对响应时间的要求并没有那么高,属于低优先级进程。

进程优先级
根据进程的重要性,可以分为:
- 实时进程(Real-Time Process)
- 普通进程(Normal Process)
在操作系统中有很多进程,实时进程是相对重要的,需要保证其CPU占用优先级,普通进程并不需要额外照顾。
实时进程和普通进程的进程优先级不同,调度器都会根据优先级来确定进程的CPU优先权和运行时间。
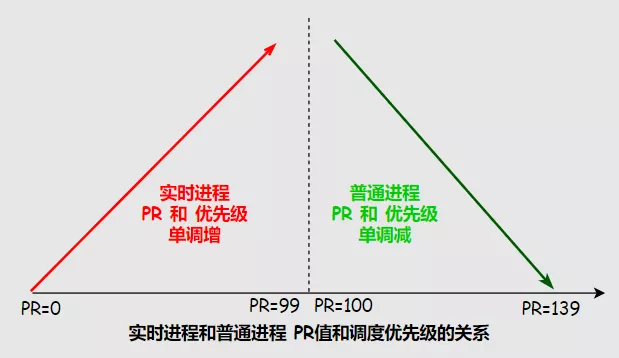
在Linux中影响优先级的两个因素:Nice谦让值和Priority权重值。
- 实时进程PR值范围是0~99,数值越大被调度优先级越高
- 普通进程PR值范围是100~139,数值越小被调度优先级越高
- Nice值范围是-20~19,并不是优先级但影响PR值,一般作用在普通进程上
PR值由内核来确定,用户可以修改Nice谦让值,进而干预PR值:
- PR_new = PR_old + Nice
nice值也被称为谦让值,数值越大越谦让,会哭的孩子有奶吃,总谦让优先级肯定低了:
- 如果nice值是0,即用户层认可内核的决定不额外干预,听天由命
- 如果nice为负值表示毫不谦让,即用户层干预来提升被调度的优先级,把机会留给自己
- 如果nice为正值表示予以谦让,即用户层干预降低被调度的优先级,把机会留给别人

非抢占和抢占式
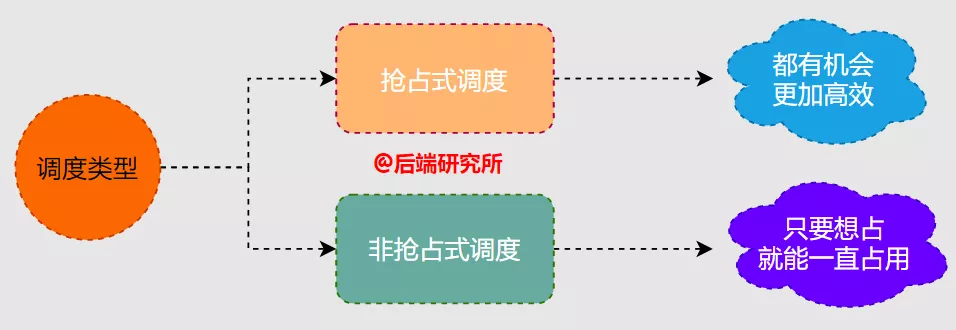
根据进程任务在占用CPU时,使用权是否会被夺取分为:
- 协作式调度( Cooperative Scheduling)
进程任务一旦占用CPU只有当任务完成或者因为某些原因主动释放CPU,除上述两种情况外不能被其他进程夺走
- 抢占式调度( Preemptive Scheduling)
进程任务占用CPU期间可以被其他进程夺走,具体由操作系统调度器决定下一个占用CPU的进程
Linux采用抢占式调度,其可以提高CPU利用率、降低进程的响应时间等,同时也增加了切换进程时的开销,各有利弊。
调度器设计思路
设计目标
有两个指标需要重视:
- 周转时间( Cycling Time )
进程任务从开始排队等待获取CPU资源直到任务完成的时间差,就像超市排队结账时从开始排队到结算完成离开的时间差。
- 响应时间Response Time
进程任务从开始排队等待获取CPU资源直到开始使用CPU的时间差,就像超市排队结账时从开始排队到轮到结算的时间差。
综合来说:
- 实时进程要更优先被调度,普通进程的优先级一定低于实时进程
- IO密集型进程要调度频繁一些,IO密集型要少分配时间片,少吃多餐
- CPU密集型可以稍微惩罚,CPU密集型可以分配长一些的时间片,少餐多吃
只有做到这几点,调度器才可能在周转时间和响应时间上得到一个良好的表现。
设计实现
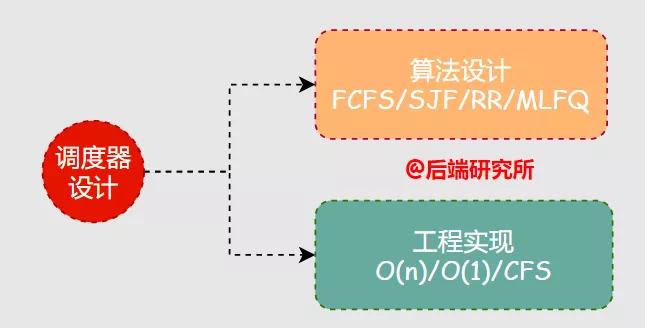
要实现一个调度器,主要包括两个核心部分:
- 算法设计
- 工程实现
算法更多是一种思想,调度器基于某种调度算法进行工程化实现,捋清楚二者的关系对于后续内容的理解将大有裨益。
本章重点
- 调度是为了解决资源和需求之间的不匹配问题,现实生活和计算机领域都非常普遍
- 操作系统可以分为:批处理系统、实时系统、分时系统三大类,分时系统是研究重点
- 进程可以分为两大类:IO密集型和CPU密集型,调度时采用不同的策略
- 进程可以分为普通进程和实时进程,实时进程优先级永远高于普通进程
- 进程调度模型可以分为两大类:协作式调度和抢占式调度,抢占式是主流
- 要设计一个进程调度器需要有设计目标后选择合适的调度算法进行工程化实现
调度算法
调度算法也经历了从简单到复杂的演进,到目前为止也没有哪种调度算法是万能的,抛开场景来评判调度算法优劣并不明智。
以下介绍的主要是调度算法的思想,工程上使用的调度算法往往是其中一种或者几种的变形,更加复杂。
先来先服务FCFS
先来先服务First Come First Service可以说是最早最简单的调度算法,哪个进程先来就先让它占用CPU,释放CPU之后第二个进程再使用,依次类推。
- 场景一
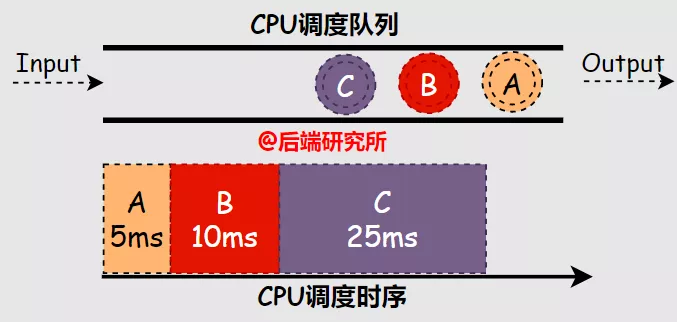
假如有ABC三个进程依次进入等候使用CPU资源的队列FIFO,A进程占用CPU运行5ms,B进程10ms,C进程25ms,根据FCFS算法的规则,可知:
- 周转时间 A-5ms B-15ms C-40ms 平均(5+15+40)/3=20ms周转时间 A-5m20+41040
- 响应时间 A-0ms B-5ms C-15ms 平均(0+5+15)/3=6.67ms
- 场景二
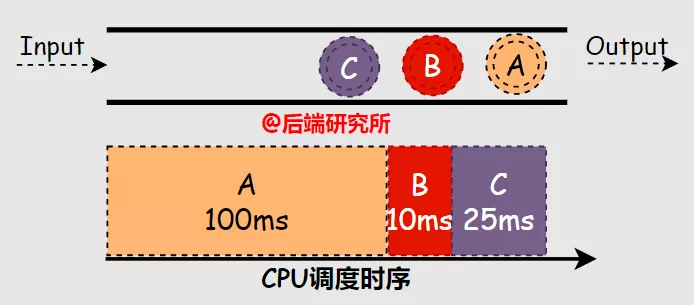
假如有ABC三个进程依次进入等候使用CPU资源的队列FIFO,A进程占用CPU运行100ms,B进程10ms,C进程25ms,根据FCFS算法的规则,可知:
- 周转时间 A-100ms B-110ms C-135ms 平均(100+110+135)/3=115ms
- 响应时间 A-0ms B-100ms C-110ms 平均(0+100+110)/3=70ms 综上,在场景二中A进程的运行时间长达100ms,这样拉升了B和C的周转时间5倍多。
在FCFS中优先被调度的进程如果耗时很长,后续进程都必须要等待这个大CPU消耗的进程,最终导致周转时间直线拉升,也就是护航效应。
最短任务优先SJF
最短任务优先Shortest Job First的思想是当多个进程同时出现时,优先安排执行时间最短的任务,然后是执行时间次短,以此类推。
SJF可以解决FCFS中同时到达进程执行时间不一致带来的护航效应问题:
- 场景一
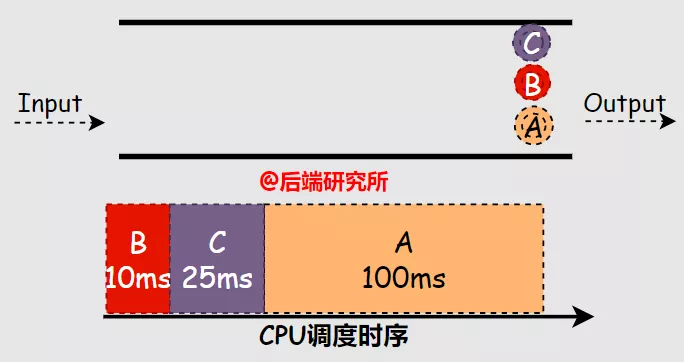
假如有ABC三个进程同时进入等候使用CPU资源的队列FIFO,A进程占用CPU运行100ms,B进程10ms,C进程25ms,根据SJF算法的规则,可知:
- 进程执行顺序是B->C->A
- 周转时间 A-135ms B-10ms C-35ms 平均(135+10+35)/3=60ms
- 响应时间 A-35ms B-0ms C-10ms 平均(35+0+10)/3=15ms
相比于FCFS可能的执行顺序是A->C->B来说,周转时间和响应时间都得到很大的改善。
SJF的算法思想有些理想化,但并非一无是处,升级改进下也有用武之地:
- 大部分场景下进程都是有先后顺序进行等待队列的,同时出现的概率并不高
- 进程执行时间的长短并不能预测
抢占式最短任务优先PSJFSJF算法最具启发的地方在于优先调度执行时间短的任务来解决护航效应,但是该算法属于非抢占式调度,对于先后到达且执行时间差别较大的场景也束手无策。
当向SJF算法增加抢占调度时能力就大大增强了,这就是PSJF( Preemptive Shortest Job First )算法。
- 场景一
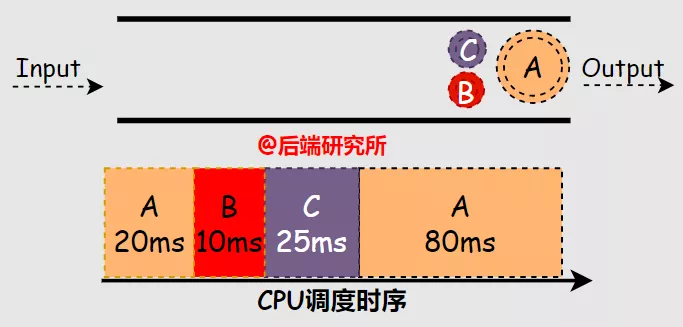
假如有ABC三个进程间隔20ms(BC同时且晚于A)依次进入等候使用CPU资源的队列FIFO,A进程占用CPU运行100ms,B进程10ms,C进程25ms,根据PSJF算法的规则,可知:
- A先被执行20ms,再执行B10ms,再执行C25ms,再执行A80ms
- 周转时间 A-135ms B-10ms C-35ms 平均(135+10+35)/3=60ms
- 响应时间 A-0ms B-0ms C-10ms 平均(0+0+10)/3=3.3ms
抢占机制有效削弱了护航效应,周转时间和响应时间都降低了许多,但是还远不够完美。
PSJF算法对于进程A来说却不友好,进程A在被抢占之后只能等待B和C运行完成后,此时如果再来短任务DEF都会抢占A,就会产生饥饿效应。
PSJF算法是基于对任务运行时间长短来进行调度的,但在调度前任务的运行时间是未知的,因此首要问题是通过历史数据来预测运行时间。
时间片轮转RR
时间片轮转RR(Round-Robin)将CPU执行时间按照时钟脉冲进行切割称为时间切片Time-Slice,一个时间切片是时钟周期的数倍,时钟周期和CPU的主频呈倒数关系。
比如 CPU的主频是1000hz,则时钟周期TimeClick=1ms, Time Slice = n*Time Click,时间切片可以是2ms/4ms/10ms等。
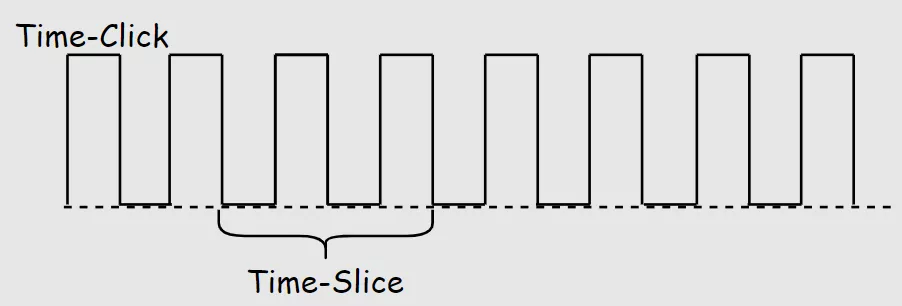
在一个时间片内CPU分配给一个进程,时间片耗尽则调度选择下一个进程,如此循环。
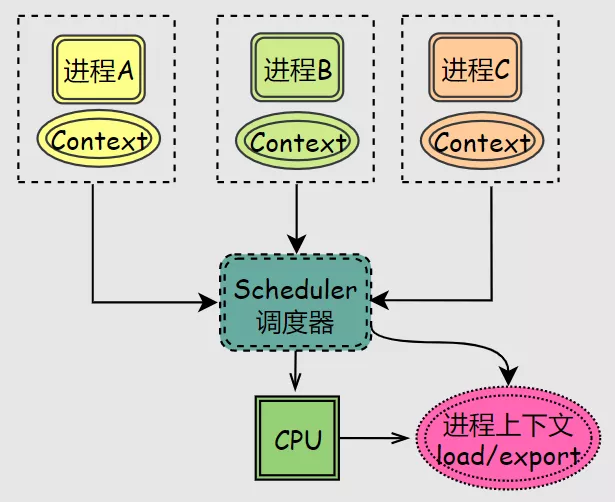
进程往往需要多个循环获取多次时间片才能完成任务,因此需要操作系统记录上一次的数据,等进程下一次被分配时间片时再拿出来,这就是传说中的上下文Context。
进程上下文被存储和拿出的过程被称为上下文切换Context Switch,上下文切换是比较消耗资源的,因此时间片的划分就显得很重要:
- 时间片太短,上下文频繁切换,有效执行时间变少
- 时间片太大,无法保证多个进程可以雨露均沾,响应时间较大
RR算法在保障了多个进程都能占用CPU,属于公平策略的一种,但是RR算法将原本可以一次运行完的任务切分成多个部分来完成,从而拉升了周转时间。
RR算法也非银弹,但是响应时间和公平性得到了有效保障,是个非常有意义的算法模型。
多级反馈队列MLFQ
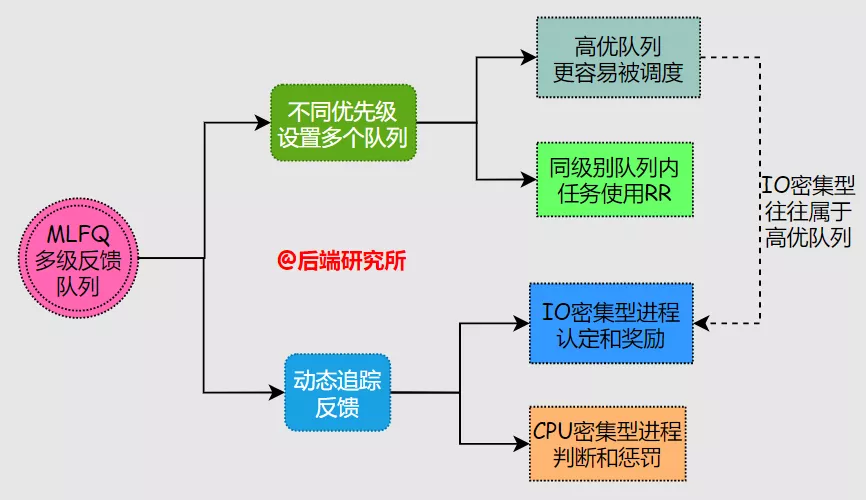
多级反馈队列( Multi-Level Feedback Queue )尝试去同时解决响应时间和周转时间两个问题,具体做法:
- 设置了多个任务队列,每个队列对应的优先级不同,队列内部的优先级相同
- 优先分配CPU给高优先级的任务,同优先级队列中的任务采用RR轮询机制
- 通过对任务运行状态的追踪来调整优先级,也就是所谓的Feedback反馈机制
- 任务在运行期间有较多IO请求和等待,预测为交互进程,优先级保持或提升
- 任务在运行期间一直进行CPU计算,预测为非交互进程,优先级保持或下降
- 最初将所以任务都设置为高优先级队列,随着后续的运行状态再进行调整
- 运行期间有IO操作则保持优先级
- 运行期间无IO操作则把任务放到低一级的队列中
- 不同队列分配不同的时间片
- 高优先级队列往往是IO型任务,配置较小的时间片来保障响应时间
- 低优先级队列往往是CPU型任务,配置较长时间片来保障任务一直运行
上述是MLFQ算法的基本规则,在实际应用中仍然会有一些问题:
- 饥饿问题
- CPU密集型的任务随着时间推移优先级会越来越低,在IO型进程多的场景下很容易出现饥饿问题,一直无法得到调度
- 任务是CPU密集型还是IO密集型可能是动态变化的,低优先级队列中的IO型任务的响应时间被拉升,调度频率下降
- 作弊问题
- 基于MLFQ对IO型任务的偏爱,用户可能为CPU密集型任务编写无用的IO空操作,从而人为提升任务优先级,相当于作弊
针对上述问题MLFQ还需增加几个补丁:
- 周期性提升所有任务的优先级到最高,避免饥饿问题
- 调度程序记录任务在某个层级队列中消耗的时间片,如果达到某个比例,无论期间是否有IO操作都降低任务的优先级,通过计时来确定真正的IO型任务
MLFQ的算法思想在1962年被提出,其作者也获得了图灵奖,可谓是影响深远。
在朴素MLFQ算法基础上出现一些变种,通过工程实现和经验配置最终被使用到操作系统中,成为真正的工业级进程调度器。
Linux进程调度器
Linux的进程调度器是不断演进的,先后出现过三种里程碑式的调度器:
- O(n)调度器 内核版本 2.4-2.6
- O(1) 调度器 内核版本 2.6.0-2.6.22
- CFS调度器 内核版本 2.6.23-至今
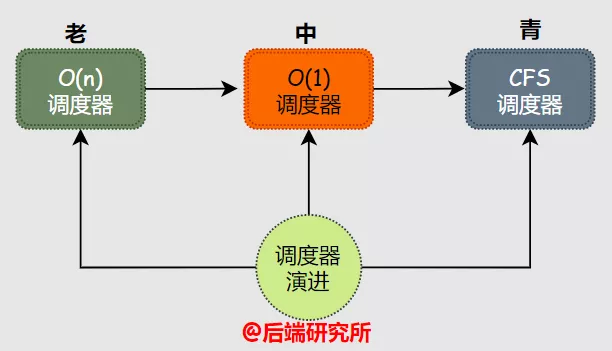
O(n)属于早期版本在pick next过程是需要遍历进程任务队列来实现,O(1)版本性能上有较大提升可以实现O(1)复杂度的pick next过程。
CFS调度器可以说是一种O(logn)调度器,但是其算法思想相比前两种有些不同,并且设计实现上也更加轻量,一直被Linux内核沿用至今。
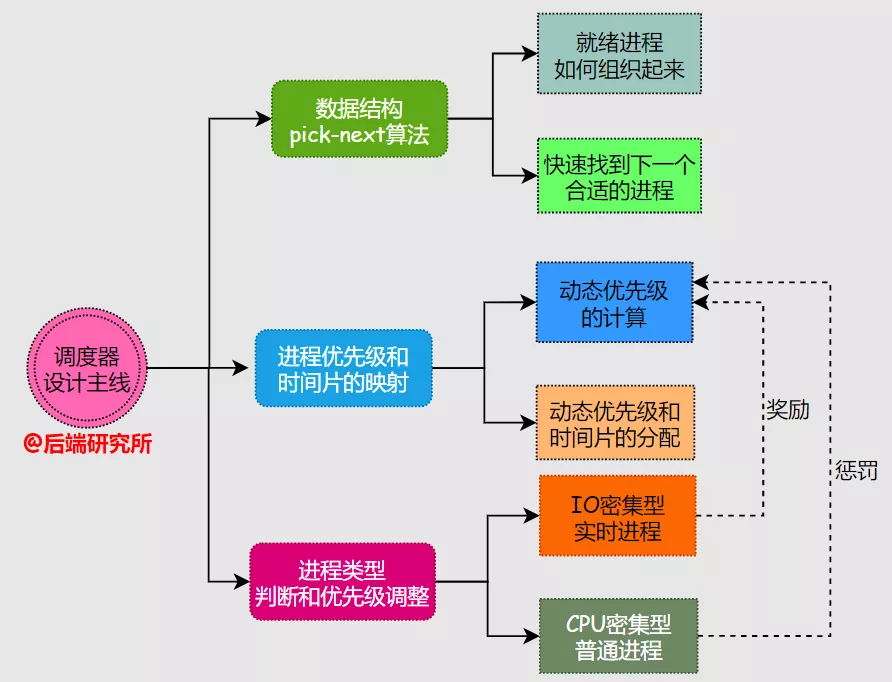
调度器设计核心
要理解这些复杂的调度器设计,我们必须要有一个核心主线,再去理解精髓。
调度器需要解决的关键问题:
- 采用何种数据结构来组织进程以及如何实现pick next
- 如何根据进程优先级来确定进程运行时间
- 如何判断进程类型
判断进程的交互性质,是否为IO密集
- 奖励IO密集型&惩罚CPU密集型
- 实时进程高优&普通进程低优
- 如何确定进程的动态优先级
影响因素:静态优先级、nice值、IO密集型和CPU密集型产生的奖惩
事实上,调度器在设计实现上考虑的问题还有很多,篇幅所限只列举几个公共问题。
O(n) 调度器
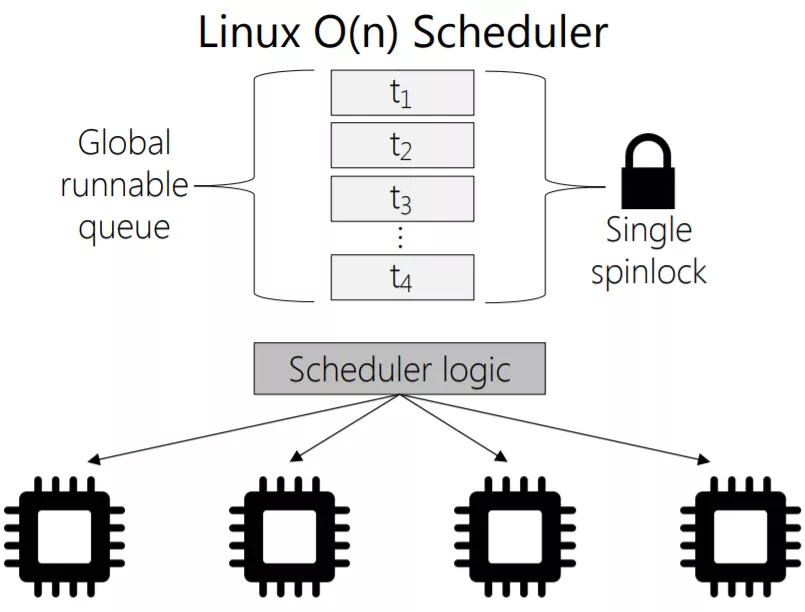
O(n)调度器采用一个全局队列runqueue作为核心数据结构,具备以下特点:
- 多个cpu共享全局队列,并非每个cpu有单独的队列
- 实时进程和普通进程混合且无序存放,寻找最合适进程需要遍历
- 就绪进程将被添加到队列,运行结束被删除
- 全局队列增删进程任务时需要加锁
- 进程被挂到不同CPU运行,缓存利用率低
在Linux中进程使用task_struct结构体来表示,其中有个counter表示进程剩余的CPU时间片:
struct task_struct {
long counter;
long nice;
unsigned long policy;
int processor;
unsigned long cpus_runnable, cpus_allowed;
}
counter值在调度周期开始时被赋值,随着调度的进行递减,直至counter=0表示无可用CPU时间,等待下一个调度周期。
O(n)调度器中调度权重是在goodness函数中完成计算的:
static inline int goodness(struct task_struct * p, int this_cpu, struct mm_struct *this_mm)
{
int weight;
weight = -1;
/*进程可以设置调度策略为SCHED_YIELD即“礼让”策略,这时候它的权值为-1,权值相当低*/
if (p->policy & SCHED_YIELD)
goto out;
/*
* Non-RT process - normal case first.
*/
/*对于调度策略为SCHED_OTHER的进程,没有实时性要求,它的权值仅仅取决于
* 时间片的剩余和它的nice值,数值上nice越小,则优先级越高,总的权值 = 时间片剩余 + (20 - nice)
* */
if (p->policy == SCHED_OTHER) {
/*
* Give the process a first-approximation goodness value
* according to the number of clock-ticks it has left.
*
* Don't do any other calculations if the time slice is
* over..
*/
weight = p->counter;
if (!weight)
goto out;
#ifdef CONFIG_SMP
/* Give a largish advantage to the same processor... */
/* (this is equivalent to penalizing other processors) */
if (p->processor == this_cpu)
weight += PROC_CHANGE_PENALTY;
#endif
/* .. and a slight advantage to the current MM */
if (p->mm == this_mm || !p->mm)
weight += 1;
weight += 20 - p->nice;
goto out;
}
/*
*对于实时进程,也就是SCHED_FIFO或者SCHED_RR调度策略,
*具有一个实时优先级,总的权值仅仅取决于该实时优先级,
*总的权值 = 1000 + 实时优先级。
* */
weight = 1000 + p->rt_priority;
out:
return weight;
}
从代码可以看到:
- 当进程的剩余时间片Counter为0时,无论静态优先级是多少都不会被选中
- 普通进程的优先级=剩余时间片Counter+20-nice
- 实时进程的优先级=1000+进程静态优先级
- 实时进程的动态优先级远大于普通进程,更容易被选中
- 剩余时间片counter越多说明进程IO较多,分配给它的没用完,被调度的优先级需要高一些
#if HZ < 200
#define TICK_SCALE(x) ((x) >> 2)
#elif HZ < 400
#define TICK_SCALE(x) ((x) >> 1)
#elif HZ < 800
#define TICK_SCALE(x) (x)
#elif HZ < 1600
#define TICK_SCALE(x) ((x) << 1)
#else
#define TICK_SCALE(x) ((x) << 2)
#endif
#define NICE_TO_TICKS(nice) (TICK_SCALE(20-(nice))+1)
NICE_TO_TICKS是个宏函数,根据不同的调度频率HZ有对应的TICK_SCALE宏定义,这样就解决了不同优先级的进程的时间片分配问题。
O(n)调度器对实时进程和普通进程采用不同的调度策略:
- 实时进程采用的是SCHED_RR或者SCHED_FIFO,高级优先&同级轮转或者顺序执行
- 普通进程采用的是SCHED_OTHER
- 进程采用的策略在task_struct中policy体现
在runqueue中搜索下一个合适的进程是基于动态优先级来实现的,动态优先级最高的就是下一个被执行的进程。
O(n)调度器设计和实现上存在一些问题,但是其中的很多思想为后续调度器设计指明了方向,意义深远。
O(1)调度器
O(n)调度器在linux内核中大约使用了4年,在Linux 2.6.0采纳了Red Hat公司Ingo Molnar设计的O(1)调度算法,该调度算法的核心思想基于Corbato等人提出的多级反馈队列算法。
O(1)调度器引入了多个队列,并且增加了负载均衡机制,对新出现的进行任务分配到合适的cpu-runqueue中:
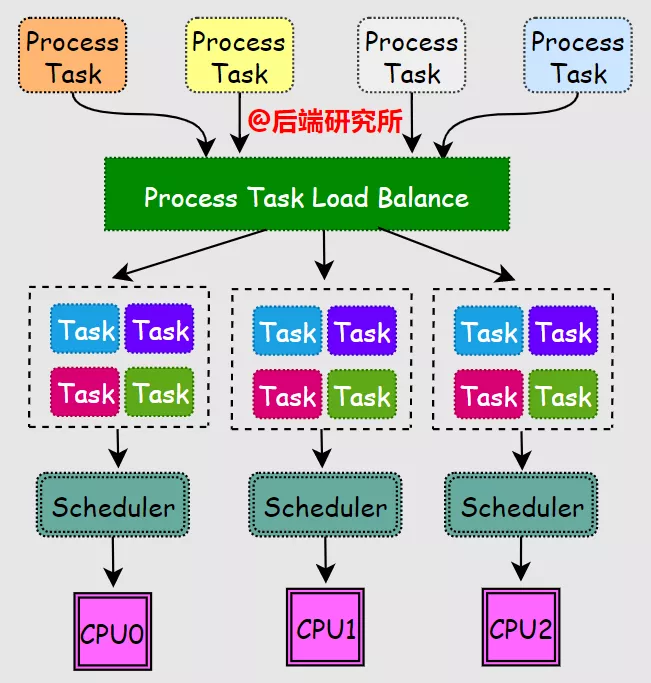
为了实现O(1)复杂度的pick-next算法,内核实现代码量增加了一倍多,其有以下几个特点:
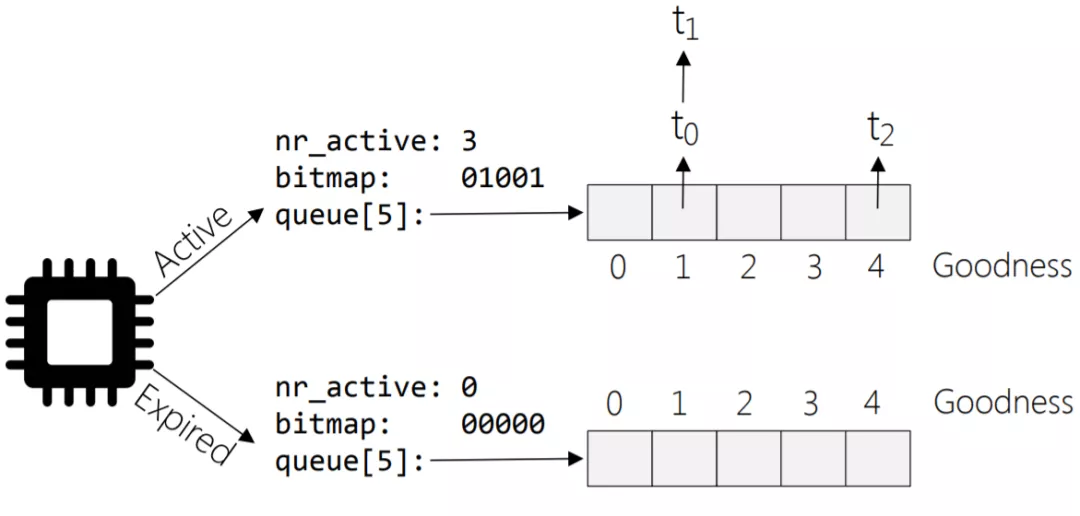
- 实现了per-cpu-runqueue,每个CPU都有一个就绪进程任务队列
- 引入活跃数组active和过期数组expire,分别存储就绪进程和结束进程
- 采用全局优先级:实时进程0-99,普通进程100-139,数值越低优先级越高,更容易被调度
- 每个优先级对应一个链表,引入bitmap数组来记录140个链表中的活跃任务情况
任务队列的数据结构:
struct runqueue {
spinlock_t lock;
unsigned long nr_running;
unsigned long long nr_switches;
unsigned long expired_timestamp, nr_uninterruptible;
unsigned long long timestamp_last_tick;
task_t *curr, *idle;
struct mm_struct *prev_mm;
prio_array_t *active, *expired, arrays[2];
int best_expired_prio;
atomic_t nr_iowait;
......
};
- active和expired是指向prio_array_t的结构体指针
- arrays是元素为prio_array_t的结构体数组
prio_array_t结构体的定义:
#define BITMAP_SIZE ((((MAX_PRIO+1+7)/8)+sizeof(long)-1)/sizeof(long))
typedef struct prio_array prio_array_t;
struct prio_array {
unsigned int nr_active;
unsigned long bitmap[BITMAP_SIZE];
struct list_head queue[MAX_PRIO];
};
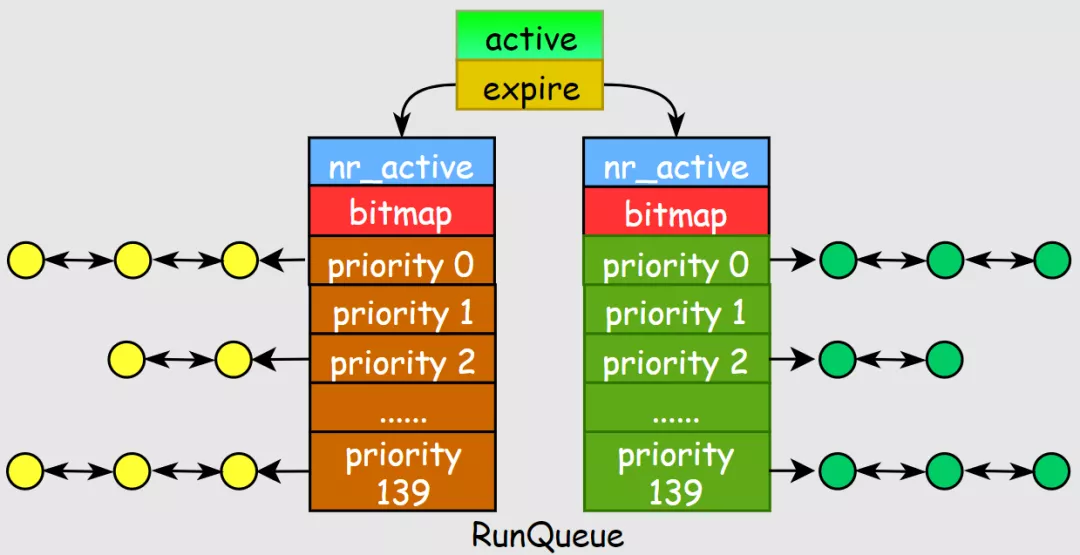
O(1)调度器对pick-next的实现:
- 在runqueue结构中有active和expire两个数组指针,active指向就绪进程的结构,从active-bitmap中寻找优先级最高且非空的数组元素,这个数组是元素是进程链表,找该链表中第1个进程即可。
idx = sched_find_first_bit(array->bitmap);
queue = array->queue + idx;
next = list_entry(queue->next, task_t, run_list);
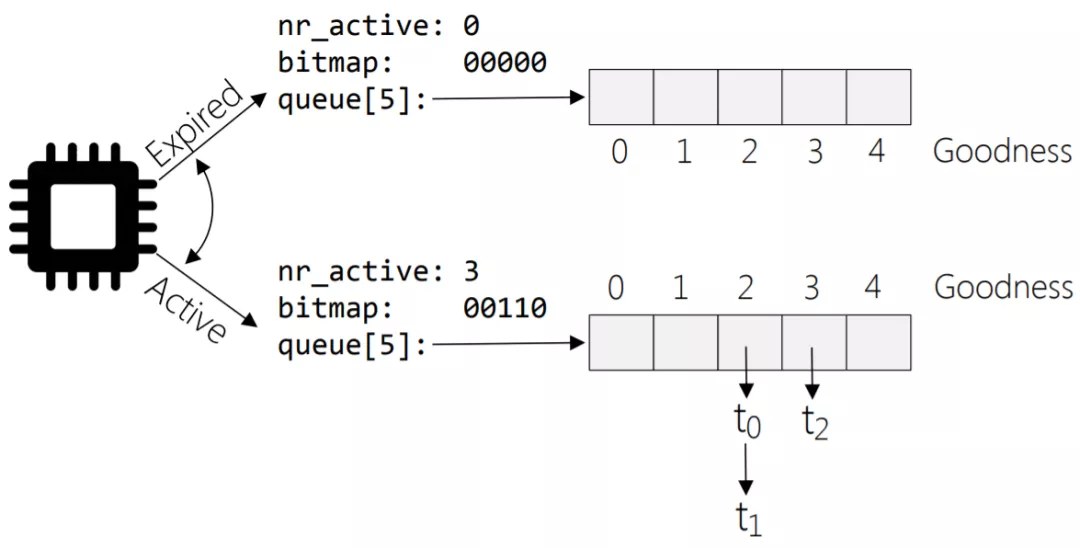
- 当active的nr_active=0时表示没有活跃任务,此时进行active和expire双指针互换,速度很快。
array = rq->active;
if (unlikely(!array->nr_active)) {
/*
* Switch the active and expired arrays.
*/
rq->active = rq->expired;
rq->expired = array;
array = rq->active;
rq->expired_timestamp = 0;
rq->best_expired_prio = MAX_PRIO;
}
O(1)和O(n)调度器确定进程优先级的方法不一样,O(1)借助了sleep_avg变量记录进程的睡眠时间,来识别IO密集型进程,计算bonus值来调整优先级:
#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20)
#define NS_TO_JIFFIES(TIME) ((TIME) / (1000000000 / HZ))
#define CURRENT_BONUS(p) \
(NS_TO_JIFFIES((p)->sleep_avg) * MAX_BONUS / \
MAX_SLEEP_AVG)
static int effective_prio(task_t *p)
{
int bonus, prio;
if (rt_task(p))
return p->prio;
bonus = CURRENT_BONUS(p) - MAX_BONUS / 2;
prio = p->static_prio - bonus;
if (prio < MAX_RT_PRIO)
prio = MAX_RT_PRIO;
if (prio > MAX_PRIO-1)
prio = MAX_PRIO-1;
return prio;
}
O(1)调度器为了实现复杂场景IO密集型任务的识别,做了大量的工作仍然无法到达100%的准确,但不可否认O(1)调度器是一款非常优秀的产品。
CFS调度器
O(1)调度器本质上是MLFQ算法的思想,随着时间的推移也暴露除了很多问题,主要集中在O(1)调度器对进程交互性的判断上积重难返。
无论是O(n)还是O(1)都需要去根据进程的运行状况判断它属于IO密集型还是CPU密集型,再做优先级奖励和惩罚,这种推测本身就会有误差,而且场景越复杂判断难度越大。
是继续优化进程交互性算法,还是另辟蹊径呢?一直困扰着Linux社区的大神们。
Con Kolivas和RSDL调度器
在CFS出现之前,不得不提一位有态度&有实力的麻醉师Con Kolivas,同时也是linux内核开发者,他在进程调度领域有自己独到的见解。
Con Kolivas针对O(1)调度器存在的维护和优化问题,提出了楼梯调度算法(Staircase Deadline Scheduler)和 基于公平策略RSDL调度器(The Rotating Staircase Deadline Schedule),遗憾的是Linux之父并没有采纳RDSL调度器。
对此Con Kolivas感到很愤怒,离开了Linux内核开发社区,但是事实上从后面CFS调度器几个版本的修订来看,Con Kolivas的大方向是正确的,离开之后的Con Kolivas又开发了BFS(Brain Fuck Scheduler)来对抗CFS调度器。
没错,BFS调度器译为脑残调度器,可见Con Kolivas的愤怒和不满。

Linux之父选择了CFS调度器,它借鉴了Con Kolivas的楼梯调度算法和RSDL调度器的经验,由匈牙利人Ingo Molnar所提出和实现,并在Linux kernel 2.6.23之后取代O(1)调度器,名震江湖。

CFS调度器
在2.6.23内核中引入scheduling class的概念,将调度器模块化,系统中可以有多种调度器,使用不同策略调度不同类型的进程:
- DL Scheduler 采用sched_deadline策略
- RT Scheduler 采用sched_rr和sched_fifo策略
- CFS Scheduler 采用sched_normal和sched_batch策略
- IDEL Scheduler 采用sched_idle策略
这样一来,CFS调度器就不关心实时进程了,专注于普通进程就可以了。
CFS( Completely Fair Scheduler )完全公平调度器,从实现思想上和之前的O(1)/O(n)很不一样。

我的脑海里浮现了这幅漫画,我想右边的应该更好,按需分配&达成共赢。
这个世界怎么会有绝对的公平呢?为啥这个调度器敢说自己是完全公平呢?
这一切CFS是如何实现的呢?我们继续看!
优先级和权重
O(1)和O(n)都将CPU资源划分为时间片,采用了固定额度分配机制,在每个调度周期进程可使用的时间片是确定的,调度周期结束被重新分配。
CFS摒弃了固定时间片分配,采用动态时间片分配,本次调度中进程可占用的时间与进程总数、总CPU时间、进程权重等均有关系,每个调度周期的值都可能会不一样。
CFS调度器从进程优先级出发,它建立了优先级prio和权重weight之间的映射关系,把优先级转换为权重来参与后续的计算:
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
普通进程的优先级范围是[100,139],prio整体减小120就和代码左边的注释对上了,也就是nice值的范围[-20,19],因此sched_prio=0相当于static_prio=120。
比如现有进程A sched_prio=0,进程B sched_prio=-5,通过sched_prio_to_weight的映射:
- 进程A weight=1024,进程B weight = 3121
- 进程A的CPU占比 = 1024/(1024+3121)= 24.7%
- 进程B的CPU占比 = 3121/(1024+3121) = 75.3%
- 假如CPU总时间是10ms,那么根据A占用2.47ms,B占用7.53ms
在CFS中引入sysctl_sched_latency(调度延迟)作为一个调度周期,真实的CPU时间表示为:
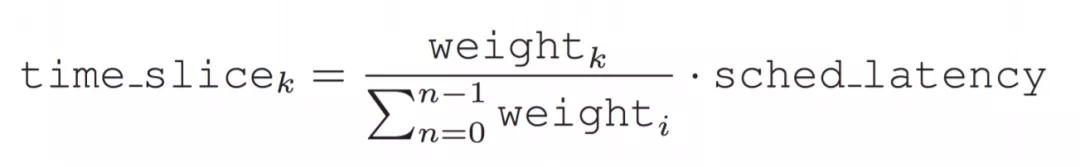
显然这样根据权重计算后的各个进程的运行时间是不等的,也就违背了”完全公平”思想,于是CFS引入了虚拟运行时间(virtual runtime)。
虚拟运行时间
每个进程的物理运行时间时肯定不能一样的,CFS调度器只要保证的就是进程的虚拟运行时间相等即可。
那虚拟运行时间该如何计算呢?
virtual_time = wall_time * nice_0_weight/sched_prio_to_weigh
比如现有进程A sched_prio=0,进程B sched_prio=-5:
- 调度延迟=10ms,A的运行时间=2.47ms B的运行时间=7.53ms,也就是wall_time
- nice_0_weight表示sched_prio=0的权重为1024
- 进程A的虚拟时间:2.47*1024/1024=2.47ms
- 进程B的虚拟时间:7.53*1024/3121=2.47ms
经过这样映射,A和B的虚拟时间就相等了。
上述公式涉及了除法和浮点数运算,因此需要转换成为乘法来保证数据准确性,再给出虚拟时间计算的变形等价公式:
virtual_time = (wall_time * nice_0_weight * 2^32/sched_prio_to_weigh)>>32
令 inv_weight = 2^32/sched_prio_to_weigh
则 virtual_time = (wall_time * 1024 * inv_weight)>>32
由于sched_prio_to_weigh的值存储在数组中,inv_weight同样可以:
const u32 sched_prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};
经过一番计算,各个进程的虚拟运行时间一致了,似乎我们理解了”完全公平”的思想。
虚拟运行时间与优先级的衰减因子有关,也就是inv_weight随着nice值增大而增大,同时其作为分母也加速了低优先级进程的衰减。
- nice=0 虚拟运行时间 = 物理运行时间
- nice>0 虚拟运行时间 > 物理运行时间
- nice<0 虚拟运行时间 < 物理运行时间
简言之:CFS将物理运行时间在不同优先级进程中发生了不同的通胀。
摒弃了固定时间片机制也是CFS的亮点,系统负载高时大家都少用一些CPU,系统负载低时大家都多用一些CPU,让调度器有了一定的自适应能力。
pick-next和红黑树
那么这些进程应该采用哪种数据结构来实现pick-next算法呢?
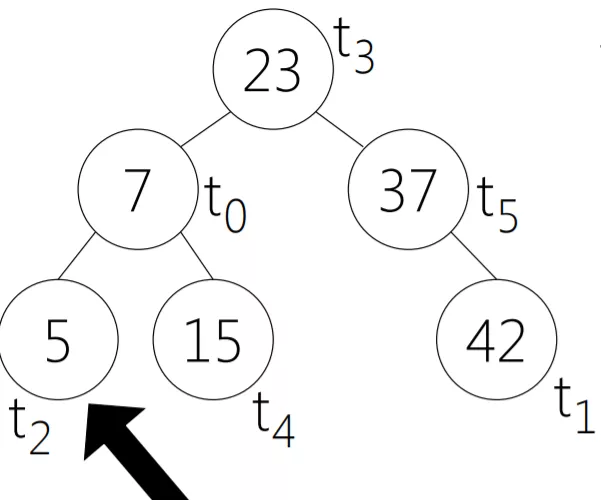
CFS调度器采用了红黑树来保存活跃进程任务,红黑树的增删查复杂度是O(logn),但是CFS引入了一些额外的数据结构,可以免去遍历获得下一个最合适的进程。
红黑树的key是进程已经使用的虚拟运行时间,并且把虚拟时间数值最小的放到最左的叶子节点,这个节点就是下一个被pick的进程了。
前面已经论证了,每个进程的虚拟运行时间是一样的,数值越小表示被调度的越少,因此需要更偏爱一些,当虚拟运行时间耗尽则从红黑树中删除,下个调度周期开始后再添加到红黑树上。

本章重点
- O(n)调度器采用全局runqueue,导致多cpu加锁问题和cache利用率低的问题
- O(1)调度器为每个cpu设计了一个runqueue,并且采用MLFQ算法思想设置140个优先级链表和active/expire两个双指针结构
- CFS调度器采用红黑树来实现O(logn)复杂度的pick-next算法,摒弃固定时间片机制,采用调度周期内的动态时间机制
- O(1)和O(n)都在交互进程的识别算法上下了功夫,但是无法做的100%准确
- CFS另辟蹊径采用完全公平思想以及虚拟运行时间来实现进行的调度
- CFS调度器也并非银弹,在某些方面可能不如O(1)
参考资料
https://cs334.cs.vassar.edu/slides/04_Linux_CFS.pdf
http://www.eecs.harvard.edu/~cs161/notes/scheduling-case-studies.pdf
http://www.wowotech.net/process_management/scheduler-history.html
 蜀ICP备20004578号
蜀ICP备20004578号