明明还有大量内存,为啥报错“无法分配内存”?
大家好,我是飞哥!
读者群里一位同学的线上服务器出现一个诡异的问题,执行任何命令都是报错“fork:无法分配内存”。这个问题最近出现的,前几次重启后解决的,但是每隔 2-3 天就会出现一次。
# service docker stop
-bash fork: 无法分配内存
# vi 1.txt
-bash fork: 无法分配内存
看到这个提示,大家的第一反应肯定是怀疑内存真的不够了。我们这位读者也是这么认为的。但查看内存占用却发现根本没有,内存还空闲了一大把!(多试几次才有机会执行成功一次)。

飞哥和群里的同学们一起参谋这个问题以后,帮出了三个思路。让这位读者回去挨个试。
1.是不是numa架构下,进程启动的时候绑定了node,导致只有一个node里的内存在起作用?
2.numa架构下,如果所有内存都插到一个槽,其它node就会没内存。
3.查看下现在的进(线)程数是多少,是不是超过最大限制了。
在经过一段时间的排查以后,这位读者的问题顺利解决。这里直接和大家汇报结论,前面关于 numa 内存不足的猜测是错误的。真实的原因是上面第 3 个,这台服务器上面的某几个java进程创建了太多的线程,导致了这个报错的产生,并不真的是内存不够。
一、底层过程分析
这个问题中,Linux 报错提示存在误导人的地方。导致大家并没有第一时间往进程数上想。所以才有了这么复杂曲折的排错过程,以至于在群里讨论才得以解决。
于是我想深入到内核里看看,报错到底是如何提示出来这么一个不恰当的错误提示的。然后顺便咱们也来了解了解创建进程的过程。
读者的线上服务器的操作系统是 CentOS 7.8,我查了一下对应的内核版本是 3.10.0-1127。
1.1 do_fork 剖析
在 Linux 内核里,无论是创建进程还是线程,都会调用到最核心的 do_fork 上来。在这个函数内部,通过拷贝的方式来创建新的进程(线程)所需要的内核数据对象。
//file:kernel/fork.c
long do_fork(unsigned long clone_flags, ...)
{
//所谓的创建,其实是根据当前进程进行拷贝
//注意:倒数第二个参数传入的是 NULL
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
...
}
整个进程创建的核心都是位于 copy_process 中,我们来看它的源码。
//file:kernel/fork.c
static struct task_struct *copy_process(unsigned long clone_flags,
...
struct pid *pid,
int trace)
{
//内核表示进程(线程)的数据结构叫task_struct
struct task_struct *p;
......
//拷贝方式生成新进程的核心数据结构
p = dup_task_struct(current);
//拷贝方式生成新进程的其它核心数据
retval = copy_semundo(clone_flags, p);
retval = copy_files(clone_flags, p);
retval = copy_fs(clone_flags, p);
retval = copy_sighand(clone_flags, p);
retval = copy_mm(clone_flags, p);
retval = copy_namespaces(clone_flags, p);
retval = copy_io(clone_flags, p);
retval = copy_thread(clone_flags, stack_start, stack_size, p);
//注意这里!!!!!!
//申请整数形式的 pid 值
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
}
//将生成的整数pid值设置到新进程的 task_struct 上
p->pid = pid_nr(pid);
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid;
bad_fork_cleanup_io:
if (p->io_context)
exit_io_context(p);
......
fork_out:
return ERR_PTR(retval);
}
通过以上代码可以看出,Linux 内核创建整个进程内核对象的创建过程都是通过分别调用不同的 copy_xxx 的方式来实现的,包括 mm 结构体、包括 namespaces等等。
我们来重点 alloc_pid 相关的这一段。在这一段中,目的是要申请一个 pid 对象出来。如果申请失败就返回错误了。大家注意这段代码的细节:无论 alloc_pid 返回的是何种类型的失败,其错误类型都写死的返回 -ENOMEM…… 为了方便大家理解,我单独把这段逻辑再展示一遍。
//file:kernel/fork.c
static struct task_struct *copy_process(...){
......
//申请整数形式的 pid 值
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
}
bad_fork_cleanup_io:
...
fork_out:
return ERR_PTR(retval);
}
在准备调用 alloc_pid 的时候,直接就先将错误类型设置成了 -ENOMEM(retval = -ENOMEM),只要 alloc_pid 返回的不正确,都是将 ENOMEM 这个错误返回给上层。而不管 alloc_pid 内存究竟是因为什么原因产生的错误。
我们来查看一下 ENOMEM 的定义。它代表的是 Out of memory 的意思。(内核只是返回错误码,应用层再给出具体的错误提示,所以实际提示的是中文的“无法分配内存”)。
//file:include/uapi/asm-generic/errno-base.h
#define ENOMEM 12 /* Out of memory */
不得不说。内核的这个错误提示太成问题了。给使用者造成了很大的困惑。
1.2 导致 alloc_pid 失败的原因
那我们接着再来详细看看都有哪些情况下分配 pid 会失败呢?来看 alloc_pid 的源码:
//file:kernel/pid.c
struct pid *alloc_pid(struct pid_namespace *ns)
{
//第一种情况:申请 pid 内核对象失败
pid = kmem_cache_alloc(ns->pid_cachep, GFP_KERNEL);
if (!pid)
goto out;
//第二种情况:申请整数 pid 号失败
//调用到alloc_pidmap来分配一个空闲的pid
tmp = ns;
pid->level = ns->level;
for (i = ns->level; i >= 0; i--) {
nr = alloc_pidmap(tmp);
if (nr < 0)
goto out_free;
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
...
out:
return pid;
out_free:
goto out;
}
我们平时说的 pid 在内核中并不是一个简单的整数类型,而是一个小结构体来表示的(struct pid),如下。
//file:include/linux/pid.h
struct pid
{
atomic_t count;
unsigned int level;
struct hlist_head tasks[PIDTYPE_MAX];
struct rcu_head rcu;
struct upid numbers[1];
};
所以需要先到内存中申请一块内存用来存储这个小对象。第一种错误情况是如果内存申请失败,alloc_pid 会返回失败。这种情况下确实是内存问题,出错后内核返回 ENOMEM 无可厚非。
接着往下看第二种情况,alloc_pidmap 是要为当前的进程申请进程号,就是我们平时所说的 PID 编号。如果申请失败,也会返回错误。
对于这种情况来说,只是分配进程编号出错了,和内存不够用半毛钱的关系都没有。但在这种情况下内核却会导致返回给上层的错误类型是 ENOMEM(Out of memory)。这实在是挺不合理的。
通过这里我们还额外学习到了另外一个知识!一个进程并不只是申请一个进程号就够了。而是通过一个 for 循环去申请了多个。
//file:kernel/pid.c
struct pid *alloc_pid(struct pid_namespace *ns)
{
//调用到alloc_pidmap来分配一个空闲的pid
tmp = ns;
pid->level = ns->level;
for (i = ns->level; i >= 0; i--) {
nr = alloc_pidmap(tmp);
if (nr < 0)
goto out_free;
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
}
假如说当前创建的进程是一个容器中的进程,那么它至少得申请两个 PID 号才行。一个 PID 是在容器命名空间中的进程号,一个是根命名空间(宿主机)中的进程号。
这也符合我们平时的经验。在容器中的每一个进程其实我们在宿主机中也都能看到。但是在容器中看到的进程号一般是和在宿主机上看到的是不一样的。比如一个进程在容器中的 pid 是 5,在宿主机命名空间下是 1256。那么该进程在内核中的对象大概是如下这个样子。
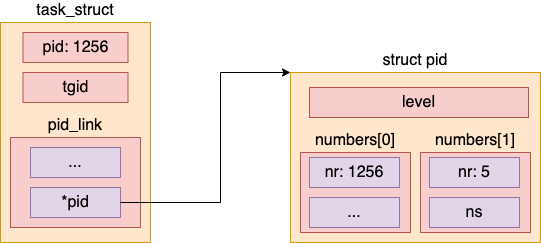
二、新版本是否有所改观
接下来,我首先想到的可能是因为咱们用的内核版本太旧了。(熟悉飞哥的读者都知道,我用的内核版本是 3.10.1,这是为了和我们公司线上服务器的版本保持一致。)
所以我又到非常新的 Linux 5.16.11 翻了一翻,看看新版本是否有修复这个不恰当的提示。
推荐一个工具:https://elixir.bootlin.com/ 。在这个网站上可以查看任意版本的 linux 内核源码。如果只是临时看一下,用它非常的合适。
//file:kernel/fork.c
static __latent_entropy struct task_struct *copy_process(...)
{
...
pid = alloc_pid(p->nsproxy->pid_ns_for_children, args->set_tid,
args->set_tid_size);
if (IS_ERR(pid)) {
retval = PTR_ERR(pid);
goto bad_fork_cleanup_thread;
}
}
貌似看起来有戏,retval 不再写死的是 ENOMEM 了,而是根据 alloc_pid 实际的错误进行了设置。我们再来看 alloc_pid 是不是正确地设置错误类型了呢?
当我打开 alloc_pid 的源码里,看到这一大段注释的时候,我的心凉了半截……
//file:include/pid.c
struct pid *alloc_pid(struct pid_namespace *ns, ...)
{
/*
* ENOMEM is not the most obvious choice especially for the case
* where the child subreaper has already exited and the pid
* namespace denies the creation of any new processes. But ENOMEM
* is what we have exposed to userspace for a long time and it is
* documented behavior for pid namespaces. So we can't easily
* change it even if there were an error code better suited.
*/
retval = -ENOMEM;
.......
return retval
}
我把这段注释给大家大致翻译一下。它的意思是“ENOMEM不是最明显的选择,尤其是对于 pid 创建失败的情况下。但是,ENOMEM 是我们长期暴露给用户空间的东西。因此,即使有更适合的错误代码,我们也无法轻易更改它”。
看到这儿,我想起了有不少人也称 Linux 为屎山,可能这就是其中的一坨吧!最新的版本里也并没有很好地解决这个问题。
结论
在 Linux 里创建进程时,如果在 pid 不足的时候竟然返回的错误提示是“内存不足”。这个不恰当的错误提示导致很多同学都困惑不已。
通过今天的文章,以后你再遇到这种内存不足错误的时候,你就要多留个心眼儿了,别被内核被蒙骗了,先来看看自己的进程(线程)数是不是过多了。
至于说发现了这个问题该如何解决嘛,可以通过修改内核参数加大可用 pid 数量(/proc/sys/kernel/pid_max)。
但是我觉得最根本的方法还是要揪出来为啥系统中会出现这么多的进程(线程),然后把它干掉。默认情况下的两三万个进程数对于绝大多数的服务器来说已经是一个过于庞大的数字了,连这个数都超过了,一定是不合理的。
 蜀ICP备20004578号
蜀ICP备20004578号