从 Linux 源码的角度解释进程
进程是操作系统中最基础的概念。《Linux内核设计》中对进程的定义”进程就是处于执行期的程序”。进程其实就是一个程序的执行过程。从计算机诞生那天开始,到现在其实架构都是冯诺依曼存储指令集的模式,没有改变。代码从编辑->编译 之后,会生成一个中间文件,有可能是二进制文件或者是一个能够被一些虚拟机识别的文件,这个文件会在特定的环境下,被载入到内存完成程序的执行,而程序在执行过程中,就被视为一个进程。
进程的生命周期
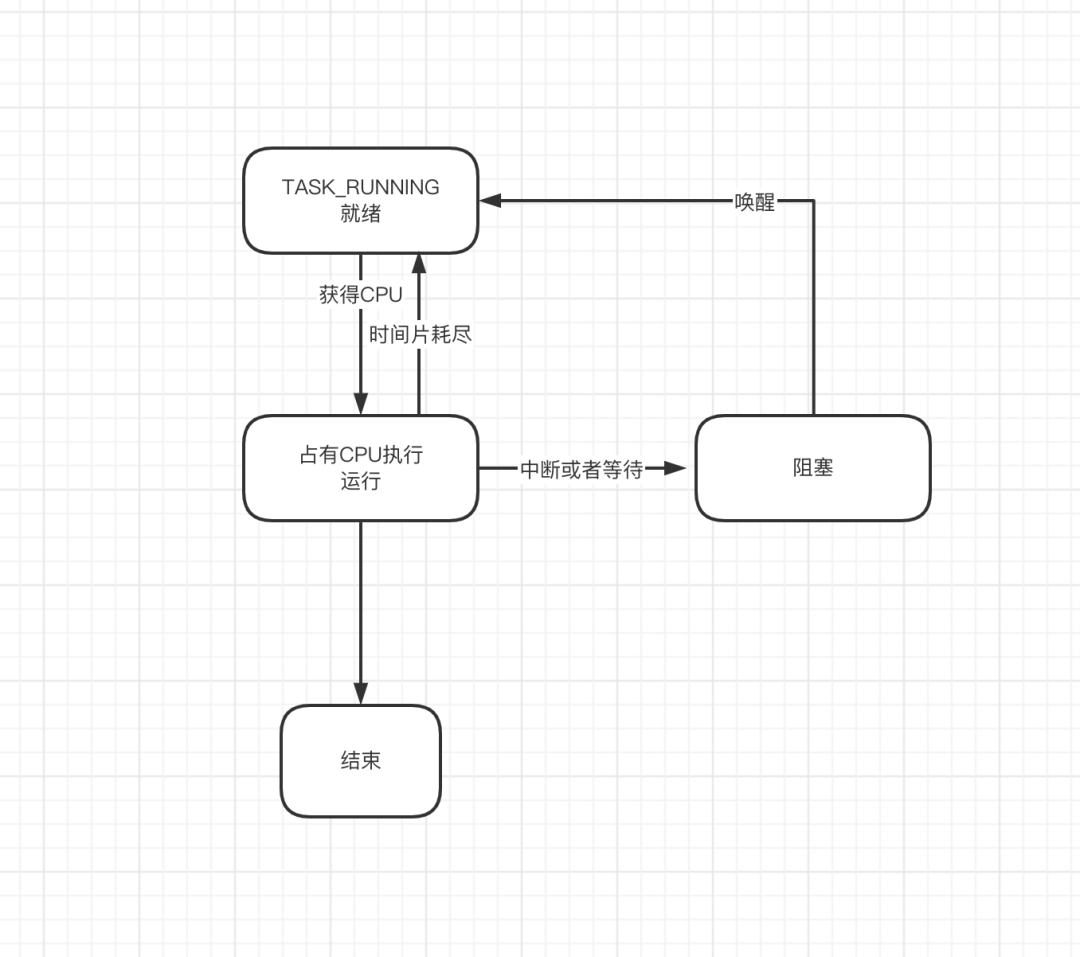
进程一般处于这四种状态中的某一种,那么当我们启动一个进程是如何启动的呢?
在Linux中,启动一个进程,一般都是由另外一个进程执行了fork调用,这个调用会从当前进程中新建一个新的进程,在Linux系统启动的时候,有一个进程是0号进程,在最开始时,所有的进程都是通过这个进程执行fork调用,来完成进程创建的。进程在执行完fork之后,会继续调用exec方法,来完成新的进程地址空间的载入和初始化,然后进入到就绪状态。进程调度器会按照一定的策略来从当前就绪的进程队列里面选择一个,分配CPU时间片,进程进入到运行态。执行过程中的进程,可能会被挂起,比如等待IO,或者直接执行完,再或者就是使用完时间片还是没执行完,这三种结果都对应着进程接下来不同的行为。
- 如果是遇到了等待条件,那么进程会被挂起,进入阻塞态。
- 如果是执行完了,那么进程进入僵死状态(注意,不是僵尸进程,只是两个概念)。进入到这个状态的进程会等待父进程的wait()调用,如果没有父进程,那么这个进程会被0号进程托管。0号进程会执行wait调用,来完成最后的退出工作。
- 如果是时间片用完了,那么进程将会再次进入就绪队列,等待下次执行。
到这里基本就描述完了进程的整个生命过程。那么接下来,将会详细描述一下上述的步骤。
进程描述符
这里有一个疑问:
进程在操作系统里面,到底是啥结构?打开Linux源码。在Linux中,每一个进程都被抽象成了task,linux使用c语言写的,c语言没有类的概念,用来描述一个复杂的结构往往使用的都是结构体:stuct。所以在linux中,进程对应的结构体就是:task_struct,在inclue/linux/sched.h里面:
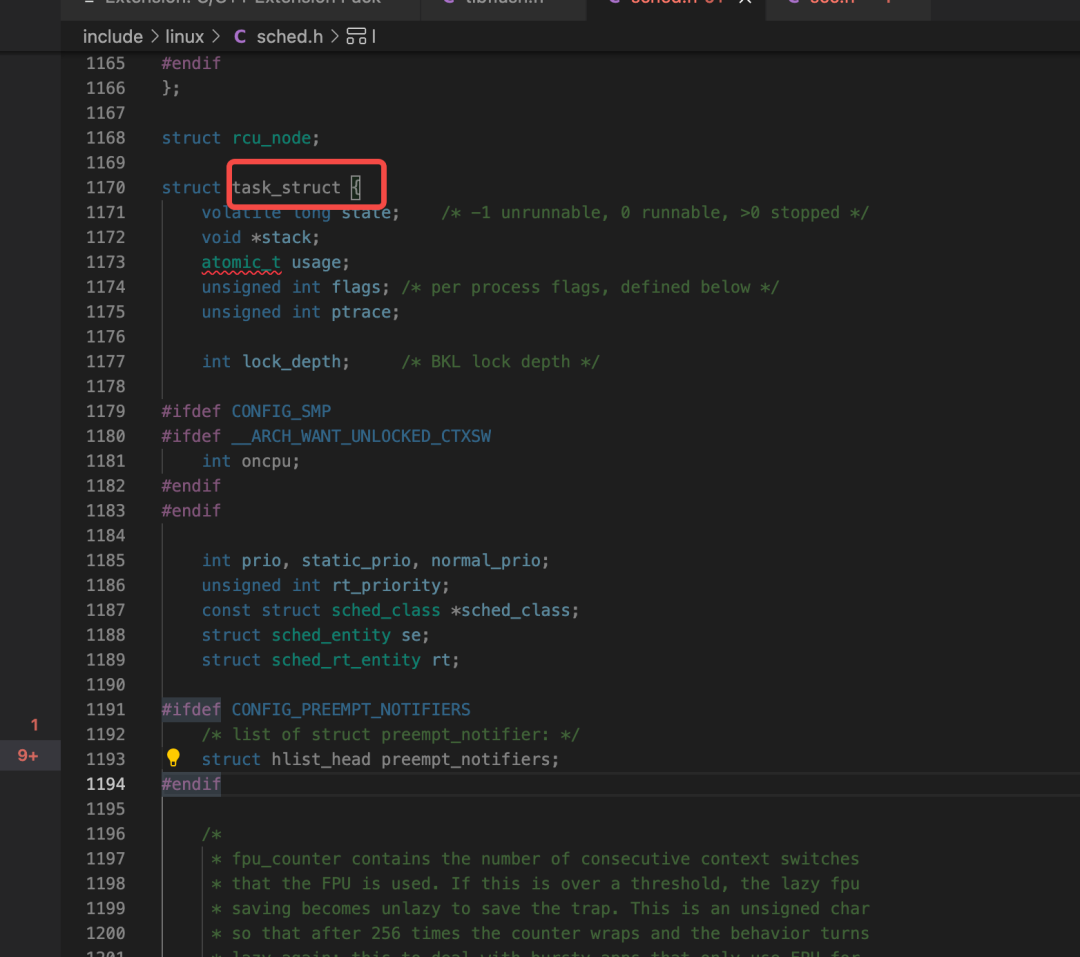
这个结构体非常的大,字段也非常多。这个结构体也被叫做:进程描述符。用来描述进程的所有性质和操作。
在这个结构体中,有几个比较重要的字段可以关注下:
进程id:pid
在task_struct 里面,有一个pid_t类型的字段:pid,这个是进程号,全局唯一的标识了某个进程。

在linux中,可以使用命令:
ps -ef
查看某个进程的pid和父进程的pid;
进程状态:state
上面说到了进程的状态,这个状态在task_struct使用了一个long类型的字段保存。

其他的还有很多,感兴趣的可以翻一下。
创建进程
那么,创建一个进程,是怎么做的呢?来看一下Linux操作系统的做法。Linux把创建进程分为两步:
- 调用fork复制当前进程描述符(task_struct)到一个新的进程,并分配pid。
- 调用exec,载入新的进程需要的资源 为什么要这样做呢?首先来看看fork做了什么。
fork调用
fork在linux内核中,调用的是kernel/fork.c中的do_fork()来完成的,看一下这个函数。
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
这个函数的参数,clone_flags代表了copy时的选项,比如是否copy地址空间,是否共享cgroup等。do_fork的逻辑比较多,但是核心逻辑是:
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
p = copy_process(clone_flags, stack_start, regs, stack_size,
child_tidptr, NULL, trace);
}
最后的调用在copy_process,这个函数会完成进程的copy,通过copy当前进程,来完成新的进程task_struct 的赋值。
copy_process
copy_process 的过程也很复杂,简化一下:
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
int cgroup_callbacks_done = 0;
// 分配一个结构体
p = dup_task_struct(current);
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
rt_mutex_init_task(p);
p->bts = NULL;
// 分配pid
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
if (clone_flags & CLONE_NEWPID) {
retval = pid_ns_prepare_proc(p->nsproxy->pid_ns);
if (retval < 0)
goto bad_fork_free_pid;
}
}
p->pid = pid_nr(pid);
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid;
if (current->nsproxy != p->nsproxy) {
retval = ns_cgroup_clone(p, pid);
if (retval)
goto bad_fork_free_pid;
}
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr: NULL;
// 设置该进程的一些cgroup选项
p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL);
p->pdeath_signal = 0;
p->exit_state = 0;
p->group_leader = p;
INIT_LIST_HEAD(&p->thread_group);
cgroup_fork_callbacks(p);
cgroup_callbacks_done = 1;
write_lock_irq(&tasklist_lock);
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
spin_lock(¤t->sighand->siglock);
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_free_pid;
}
total_forks++;
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
perf_event_fork(p);
return p;
}
copy_process 简化之后,大概做了这么几件事情:
- 调用dup_task_struct,为新的子进程创建一个结构体实例。
- 分配pid。
- 设置该子进程的特有成员,和父进程区别开来。
- 返回结构体。
从这个函数可以看出来,其实copy_process做的事情,都是一些很轻量级的,只涉及到部分字段的copy,对于进程的地址空间,占有的内存,是没有做copy的。这正是fork调用的性能比较高的原因。
cow写时复制
从上面可以看出,fork其实只是copy可一些轻量级的结构,对于进程所持有的内存,fork完之后,新进程和父进程是共享的。很多人没法明白这里,简单画个图:
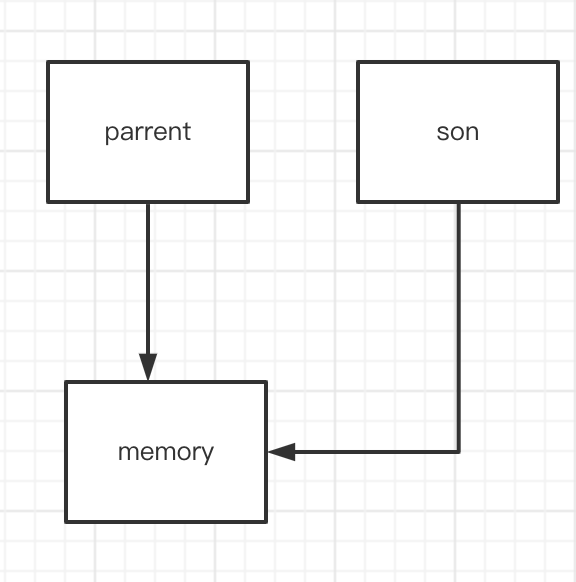
在fork完之后,得到的task_struct结构体其实是一个浅拷贝。父子进程同时持有指向地址空间的指针,并且是同一个指针,这就导致二者会访问同一个地址空间。如果二者同时开始写这个地址空间,那么就会产生数据问题。如果直接在fork的时候,就做深拷贝,那么fork调用开销其实非常严重。Linux为了解决这个问题,使用了写时复制技术(Copy On Write)。
写时复制顾名思义就是写的时候再去复制。对应到这里就是,子进程在读共享内存的时候,是不复制的,如果修改的时,是需要复制一块新的内存出来。这也是一种惰性修改这种场景对于哪些只读不写的子进程,比如Redis在做RDB快照的时候,fork出来的子进程就是只读不写的,这样的场景非常适合。
cow既保证了fork的高性能,但是有些场景下,子进程在新建之后,会载入自己的地址空间,比如自己新开辟内存做一些事情,不需要和父进程共享,这也是大多数的场景。这个时候如果父进程优先去写共享内存,那么其实也是会发生内存拷贝的,这也是不必要的开销。为了解决这个问题,linux操作系统做了一个优。
fork完之后,立刻调用子进程exec函数,来执行子进程逻辑,并且是有意让子进程优先执行。
结合上面的描述,我想这个优化不难理解。到这里,一个进程就算是被创建完成了。
Linux线程
在Linux中,其实没有线程这个概念,这和其他操作系统区别比较大,Linux的线程和进程其实是一个东西,都是使用task_struct来描述,只是里面的成员赋值有所区别。现在大部分的概念,都说线程是轻量级进程这个说法的来源,其实指的就是,新建出来的这个被视为线程的进程,大部分的资源都是和父进程共享的,不允许自己去写时拷贝。使用当前进程的地址空间来完成。所以你会发现,在使用线程的时候,可能会产生竞态条件,要做同步之类的,这就是因为,新建出来的线程,是共享当前进程资源的!
进程调度
在创建完进程之后,进程就会接入就绪状态,等待调度。调度指的是操作系统按照一定的策略,把cpu分配给进程,让他们使用cpu来执行任务。
抢占式调度和协作式调度
Linux进程调度有多种策略,但是策略核心思想只有两个,要么是抢占式调度要么是协作式调度。
- 抢占式调度:指的是调度程序可以强制的挂起某个任务,然后让下一个任务继续执行。
- 协作式调度:协作式调度指的是进程需要主动的让出(yielding)cpu,然后其他进程继续执行。
Linux是从开始设计就是抢占式调度的思想,协作式调度会出现很多问题,例如进程在陷入内核之后,获取cpu执行,如果出现长时间等待不让出cpu,那么系统就会陷入忙等待时间,其他任务进入饥饿状态。抢占式调度可以更好地控制每个进程使用cpu的时间。
进程优先级和时间片
既然是抢占式调度,那么就有几个问题。
- 何时挂起当前任务?
- 挂起之后下一个选择那个任务继续执行?
关于这两个问题,Linux引入了两个概念:
- 时间片:时间片指的是进程运行多少时间。在Unix系统里面,时间片和nice值一一对应。nice值得取值范围是[-19.20],并且值越大,优先级越低!
- 进程优先级:每个进程都有一个优先级,优先级高的获得的时间片会更多,就会更加频繁的运行。
有了这两个概念,就可以完成进程调度了。
例如,nice值=0代表可运行100ms,nice值=20代表可以运行5ms。那么考虑下面两个场景:
- 一个nice值=0和一个nice值=20,那么nice=0的进程会运行100ms,nice=20的会运行5ms,在105ms内,有了一次进程上下文切换,可以接受。
- 两个nice=20的进程,那么在10ms内就会有两次上下文切换,这显然会浪费很多计算资源。
早期 linux 的调度方法,确实是这样做的。在linux2.6之后,提出了完全公平调度策略CFS(Completely Fair Schedule). 代码在kernel/sched_fair.h中。
CFS
CFS主要有四个组成部分:
- 时间记账
- 进程选择
- 调度器入口
- 睡眠与唤醒
时间记账
CFS不再使用时间片的概念,而是转为对每个进程运行的时间做记账
在incude/kernel/sched.h中:sched_entity记录了这些信息。
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 last_wakeup;
u64 avg_overlap;
u64 nr_migrations;
u64 start_runtime;
u64 avg_wakeup;
}
其中sum_exec_runtime 就是对进程运行时间的记录。但是CFS直接关注不是sum_exec_runtime,而是它下面的那个字段:vruntime。这个叫做进程虚拟运行时,CFS根据虚拟运行时来调度进程。
vruntime 虚拟运行时
虚拟运行时是进程真实运行时间加权之后的结果,简化计算公式:
curr->vruntime += (delat_exec * 1024)/ curr->load->weight
delta_exec是真实运行时间。
vruntime 更新
vruntime的更新是在:kernel/sched_fair.h中:
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_of(cfs_rq)->clock;
unsigned long delta_exec;
if (unlikely(!curr))
return;
/*
* Get the amount of time the current task was running
* since the last time we changed load (this cannot
* overflow on 32 bits):
*/
delta_exec = (unsigned long)(now - curr->exec_start);
if (!delta_exec)
return;
__update_curr(cfs_rq, curr, delta_exec);
curr->exec_start = now;
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cpuacct_charge(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
}
这个函数会更新sched_entity中的相关信息。
进程选择
上面讲述了虚拟运行时是如何被计算和更新的,那么CFS如何使用vruntime去选择下一个被调度的进程呢?
CFS每次会选取vruntime最小的那个进程来分配CPU
这里简单描述一下为啥这样做,因为CFS讲的是完美公平调度,但是由于时钟延迟,其实完美公平是不存在的,只能尽量公平。首先每个进程都有一个权重,这个权重是nice值决定的,nice值越小,权重越高。根据计算公式,权重越高,每次运行相同的时间,vruntime增加的幅度越小。
举个例子, 两个进程AB,A权重是10,B权重是100,同时运行100ms,那么对于A的vruntime增加是10,但是对于B的vruntime增加是1,CFS每次选取vruntime最小的去执行,所以B会被优先选上,相当于B执行10次,A才会被执行一次,这也和权重呼应起来。
那么还有一个问题,怎么知道哪个进程vruntime最小呢?
上面提到了,每个进程都有一个唯一的进程编号:pid,所以可以按照这个组成一个进程队列,然后排序,每次取最小的。这样可以是可以,但是每次更新完之后就要重新排序,这显然对操作系统这种对性能要求很高的软件是不可接受的。那么如何支持高效的查找最小值,并且可以动态更新呢?
答案是红黑树!看到这里可能有人要害怕了,其实红黑树没有那么难,只是很多人不知道具体的应用场景。Linux使用红黑树来组织可运行的进程队列,每次选取红黑树最左边的叶子节点出来运行,运行完之后再放回去。
static struct sched_entity *pick_next_entity(struct cfs_rq *cfs_rq)
{
struct sched_entity *se = __pick_next_entity(cfs_rq);
struct sched_entity *left = se;
if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1)
se = cfs_rq->next;
/*
* Prefer last buddy, try to return the CPU to a preempted task.
*/
if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1)
se = cfs_rq->last;
clear_buddies(cfs_rq, se);
return se;
}
到这里就完成了具体的选择逻辑。篇幅有限,就暂时不说如何更新树里面的节点了。
进程退出
进程在执行完自己的任务之后,就要退出了。退出工作是由:kernel/exit.c完成的。主要有:
- 设置task_struct state字段为PF_EXISTING
- 释放内存空间
- 删除引用的资源描述符
- 调用exit_notify,告诉父进程退出,如果父进程已经退出,那么发送给init进程
- 触发schedule(),调度新的进程
完成这些操作之后的进程处于:EXIT_ZOMBIE状态,这个状态下的进程不会再被调度器调度。
孤儿进程
如果进程退出时发现父进程已经退出了,那么这种进程就被叫做孤儿进程。孤儿进程在退出的时候,会给父进程发送信号,等待父进程的wait调用。如果没有父进程,那么孤儿进程中的task_stauct资源将会无法回收,为了解决这个问题,在进程调用exit_notify()时,会判断父进程是否存在,如果不存在,会执行forget_original_parent(),然后托管给0号进程,也就是init进程。
forget_original_parent:
static void forget_original_parent(struct task_struct *father)
{
struct task_struct *p, *n, *reaper;
LIST_HEAD(dead_children);
exit_ptrace(father);
write_lock_irq(&tasklist_lock);
reaper = find_new_reaper(father);
list_for_each_entry_safe(p, n, &father->children, sibling) {
struct task_struct *t = p;
do {
t->real_parent = reaper;
if (t->parent == father) {
BUG_ON(task_ptrace(t));
t->parent = t->real_parent;
}
if (t->pdeath_signal)
group_send_sig_info(t->pdeath_signal,
SEND_SIG_NOINFO, t);
} while_each_thread(p, t);
reparent_leader(father, p, &dead_children);
}
write_unlock_irq(&tasklist_lock);
BUG_ON(!list_empty(&father->children));
list_for_each_entry_safe(p, n, &dead_children, sibling) {
list_del_init(&p->sibling);
release_task(p);
}
}
重新寻找parent: find_new_reaper():
static struct task_struct *find_new_reaper(struct task_struct *father)
{
struct pid_namespace *pid_ns = task_active_pid_ns(father);
struct task_struct *thread;
thread = father;
while_each_thread(father, thread) {
if (thread->flags & PF_EXITING)
continue;
if (unlikely(pid_ns->child_reaper == father))
pid_ns->child_reaper = thread;
return thread;
}
if (unlikely(pid_ns->child_reaper == father)) {
write_unlock_irq(&tasklist_lock);
if (unlikely(pid_ns == &init_pid_ns))
panic("Attempted to kill init!");
zap_pid_ns_processes(pid_ns);
write_lock_irq(&tasklist_lock);
/*
* We can not clear ->child_reaper or leave it alone.
* There may by stealth EXIT_DEAD tasks on ->children,
* forget_original_parent() must move them somewhere.
*/
pid_ns->child_reaper = init_pid_ns.child_reaper;
}
return pid_ns->child_reaper;
}
结尾到这里进程的生命周期基本讲完了,从怎么创建进程到进程调度到退出。
 蜀ICP备20004578号
蜀ICP备20004578号