从 NIO 到 Netty
IO 是编程中一个重要的概念,不论是数据存储和网络通信,底层都是会用到,理解 IO 对面试和工作都有很大的帮助,也能从基础理论层面扎实基础,理解其上层应用就简单的多了。在常用的软件中,例如 Nginx、Redis、Dubbo、Kafka 都涉及到了 NIO 的一些基础知识,本文就从简单的 IO 开始剖析,从 BIO 到 NIO 再到 Netty,从理论到实践进行深入的理解。
计算机组成
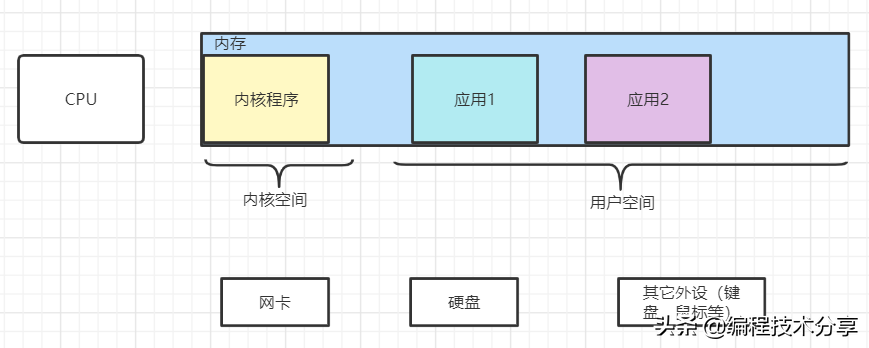
计算机的组成包括 CPU、内存存储、网卡、磁盘存储和其它外部设备。在 Linux 操作系统中,一切皆文件(即文件描述符 fd,file descriptor),在服务启动时,会加载内核程序到 CPU 中运行。为了保证服务的正常运行,内核程序具有较高的优先级,所占用的空间为内核空间,其它应用程序所占用的空间为用户空间。以 Java 程序为例来讲,其也是一个程序并且占用一定的内存空间,在应用运行过程中,如果有 IO 操作或者计算需求,则需要将其转交给内核程序来完成。因为内核(kernel)保护模式的存在,应用程序是没有权限调用 CPU 的,一切的操作都需要通过内核程序来完成,只有这样才能保证一旦应用程序错误,内核程序不会受影响,整个系统就没有宕机的风险。
内核程序和应用程序之间通过中断(通常的有 80 中断)来完成操作的切换,应用系统通过内核程序提供的系统调用(System Call,是一系列的系统操作函数,是内核系统暴露出来的 API)来实现对 CPU 或 IO 的操作,CPU 通过 FCFS(非抢占式的先来先服务算法)分配各个任务的时间片,来实现各个任务并发运算。在 Java 的多线程应用中,有个上下文切换的概念,这就是应用线程将任务切换到内核线程,在 CPU 的时间片内继续进行操作,完成操作后将内核线程切换到应用线程。
进程是系统分配资源的基本单位,线程是 cpu 执行调度的基本单位,线程也称之为轻量级的进程(LWP)。java 的线程就是通过内核的系统调用,在操作系统中获取到的轻量级进程。
阻塞与非阻塞/同步与异步
这里线说一下小编理解的阻塞与非阻塞以及同步和异步的概念:
阻塞和非阻塞描述的是用户线程调用内核 IO 操作的方式,阻塞是发起调用后需要等待直至内核给出结果数据是否可读可写,非阻塞是发起用调用后无需等待结果,给出状态值-1 表示正在处理。
同步和异步描述的是用户线程和内核的交互数据的方式,同步是需要用户线程自己获取数据,即使是多路复用器也是解决了阻塞的问题,还需要用户线程自己获取数据,依旧是同步 IO 模型。而异步是用户线程发起调用后不需要主动获取数据,而是内核处理完毕后将数据放入用户空间中再通知用户线程继续业务处理。
在常见 socket 编程中,如下所示:
//把Socket服务端启动
ServerSocket server = new ServerSocket(8986);
while (true) {
// 阻塞方法,等待客户端的接入
Socket client = server.accept();
// 得到输入流
InputStream input = client.getInputStream();
// 建立缓冲区
byte[] buff = new byte[4096];
int len = input.read(buff);
// 只要一直有数据写入,len就会一直大于0
if (len > 0) {
String msg = new String(buff, 0, len);
System.out.println("收到" + msg);
}
}
在操作系统中运行使,如何监听其操作系统级别的指令呢?首先需要将创建 java 文件
# 创建 java 文件
Bio001Test.java
# 然后使用 javac 命令编译成 Bio001Test.class
javac Bio001Test.java
# 执行java 代码
java Bio001Test
# 使用 strace 命令进行监听系统调用的情况,其底层是使用内核的ptrace 特性来实现的
strace -ff -o out java Bio001Test
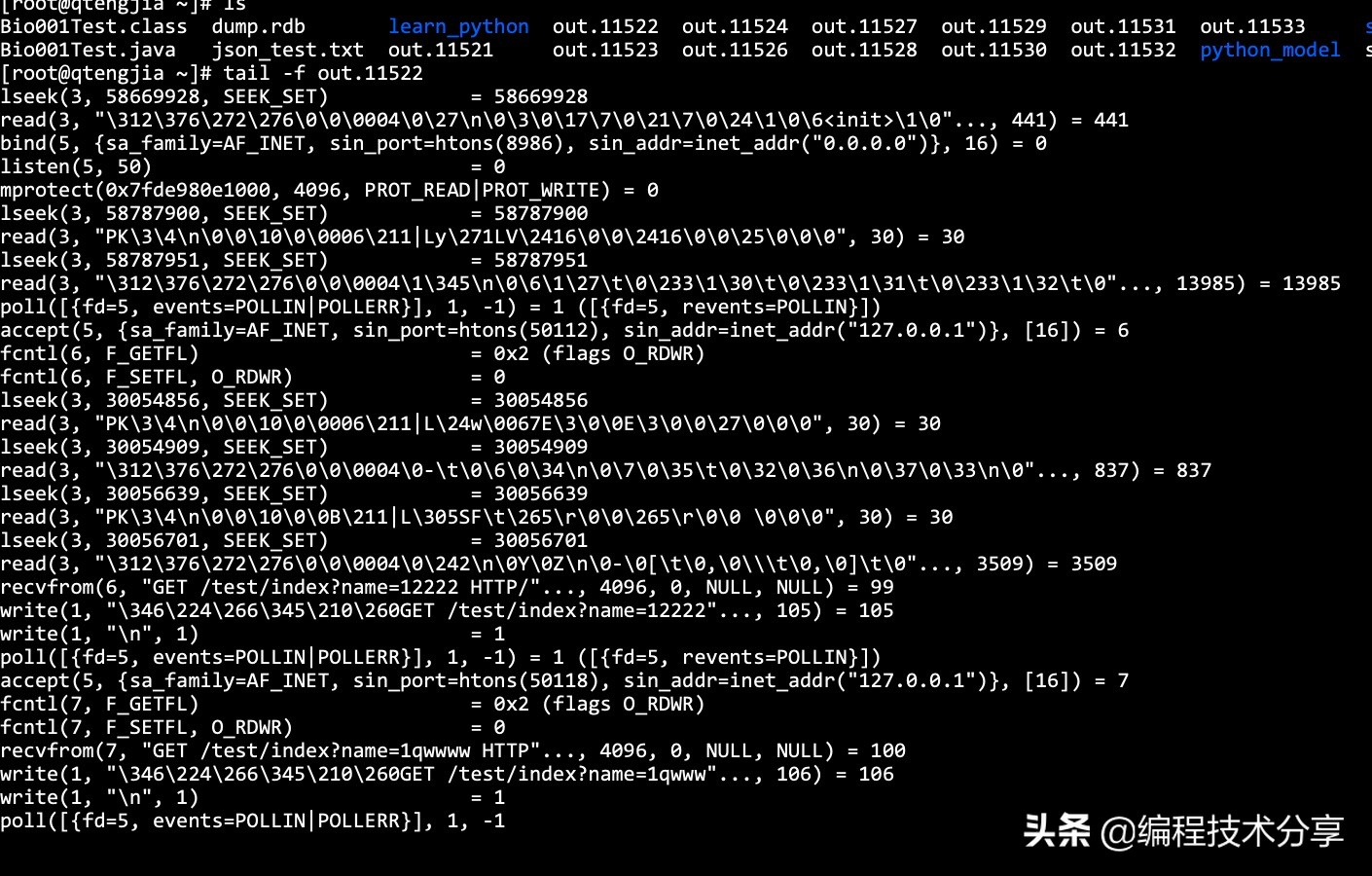
下图是 java 代码打印出的信息,显示了 http 的请求记录:
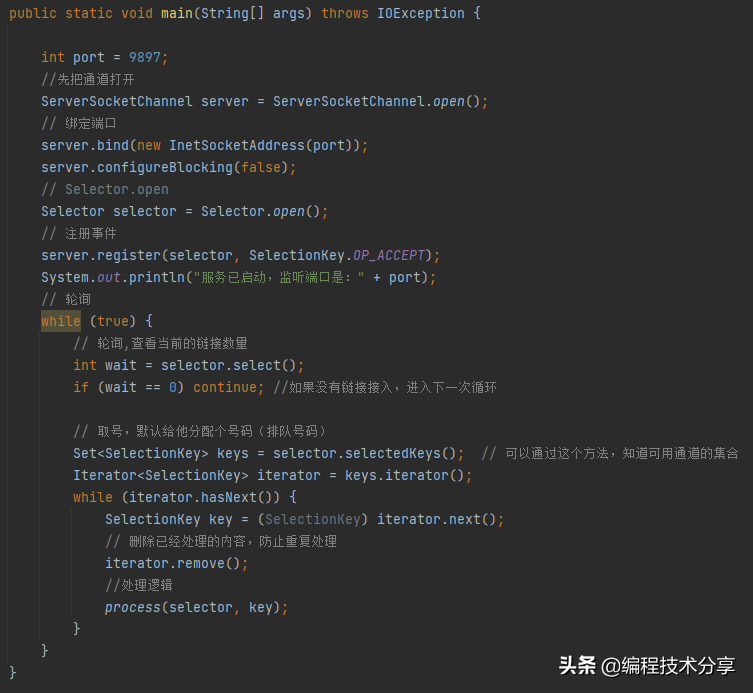
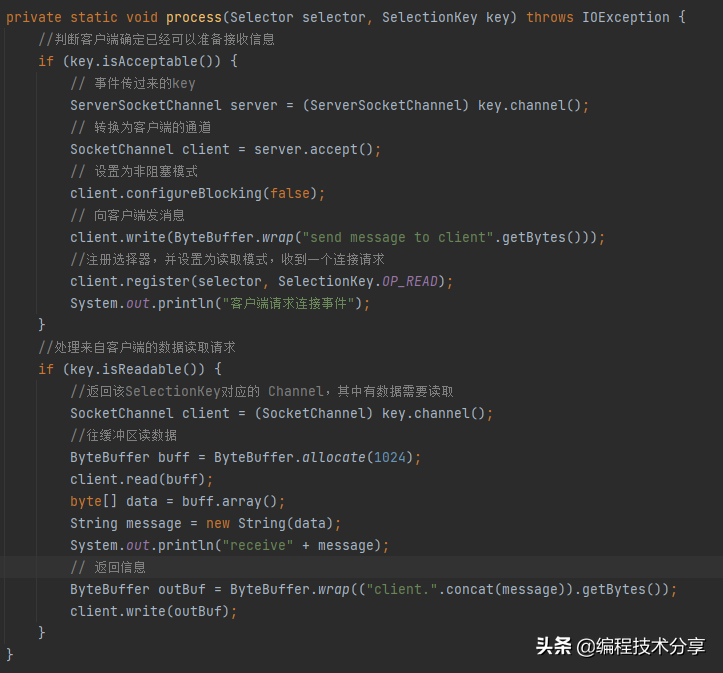
相比 BIO 的代码, NIO 的代码就比较复杂了,BIO 是阻塞的,NIO 是非阻塞的, BIO 是面向流的,只能单向读写,NIO 是面向缓冲的, 可以双向读写。
# bio 的阻塞方法
server.accept()
# nio 的非阻塞方法,提出 channel selector buffer 的概念来解决io,利用事件注册状态来处理请求信息
selecter.select()
使用 man socket 来查看操作系统中 socket 传入的参数,如下所示:
# 操作系统的函数都是 C 语言编写的,java 也是类C 的语言
socket()
# 创建一个用于通信的文件描述符
creates an endpoint for communication and returns a descriptor.
...
# 设置非阻塞参数项
SOCK_NONBLOCK
Set the O_NONBLOCK file status flag on the new open file description. Using this flag saves extra calls to fcntl(2) to achieve the same result.
socket 称之为套接字、或者插座,属于网络应用程序接口。即是应用层到传输层的接口,也是用户进程与系统内核交互的接口。一个 TCP 连接的标记为四元组,即源 ip:源 port + 目标 ip:目标 port, 我们都知道计算机的端口范围为 0-65535,也就是说一个客户端最多可以向目标服务器发起 65535 个连接。
BIO 的模型
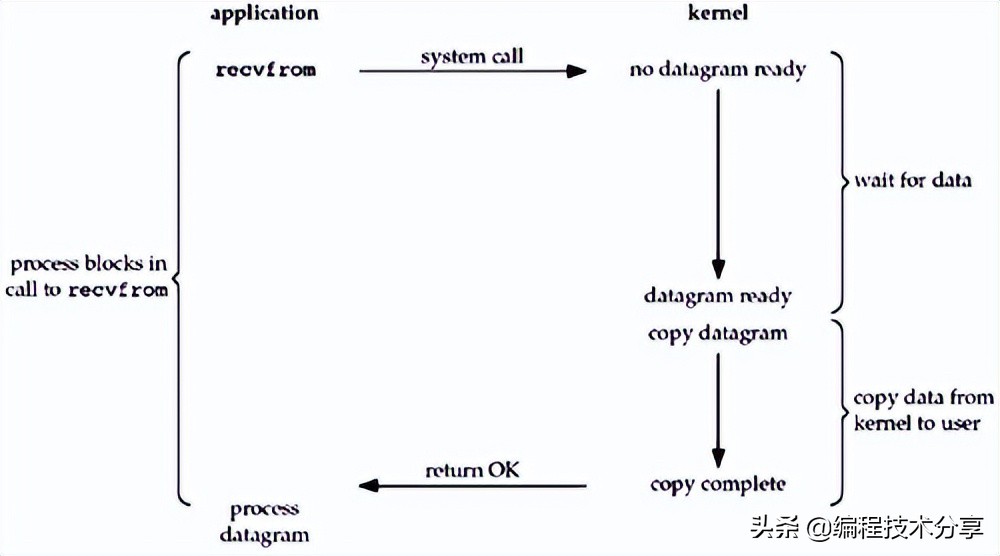
当应用发起调用后,在 kernel 没有准备好数据之前,应用进程一直会阻塞 block 进入等待阶段,当 kernel 准备好数据之后,才会返回数据,此时应用进程阻塞解除。
NIO 的模型
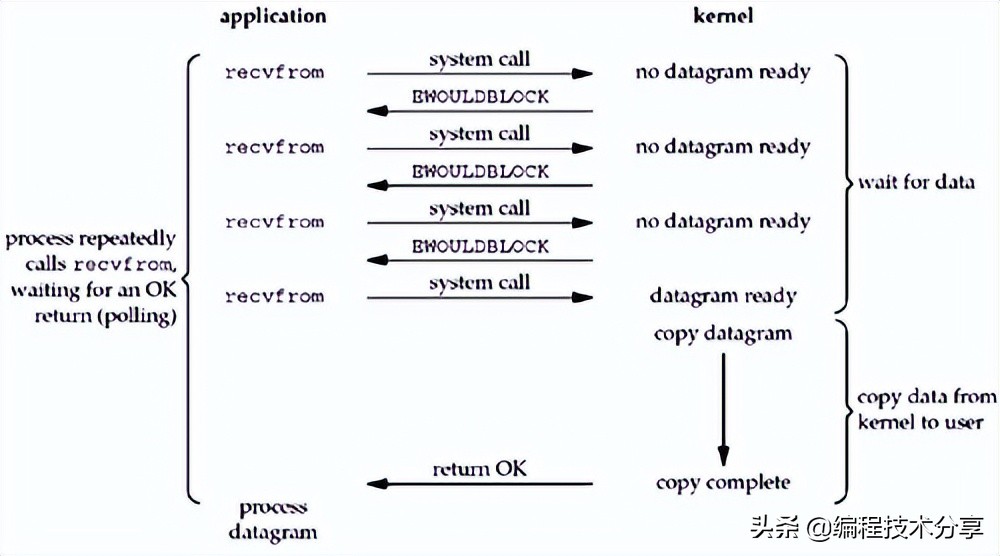
因为 kernel 是阻塞的,在引入了 nio 之后,在应用发起调用后会立即返回结果-1,代表内核尚未准备好数据,应用进程无需等待,可以轮询查看结果,直到数据准备好为止,此时应用进程阻塞获取数据。
多路复用器
即便是 nio 解决了阻塞的问题,但是无效的轮询会造成 cpu 空转,浪费资源,使用 IO 多路复用技术,当内核将数据准备好之后,通知应用进程来获取数据,就解决了这个问题,根据其操作的方式不同,分为 select/poll/epoll 三种多路复用器。 由内核 kernel 监控所有的 socket 当数据准备好之后,发起系统调用,即 system call 将数据从内核拷贝到用户进程。
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
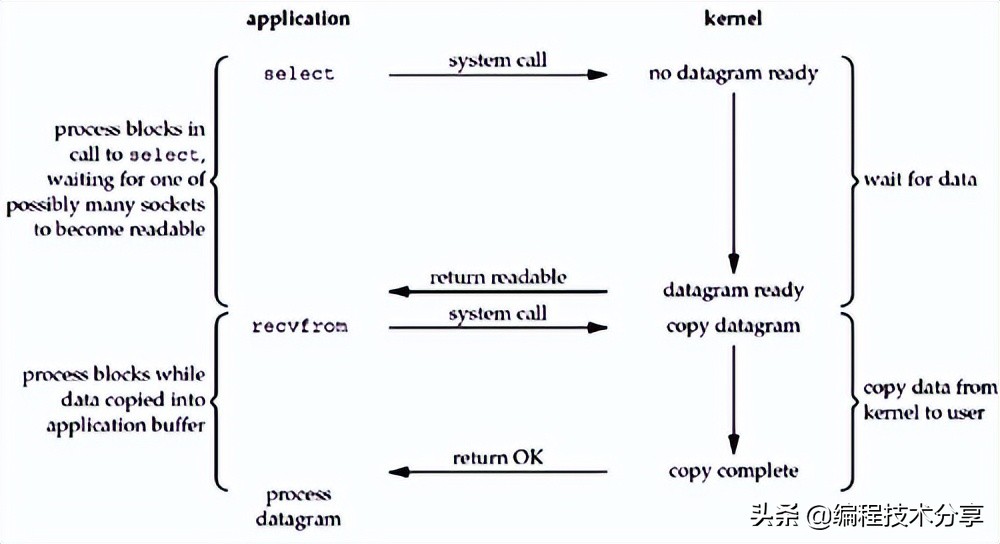
I/O 多路复用的优势是:同时处理多个连接请求。
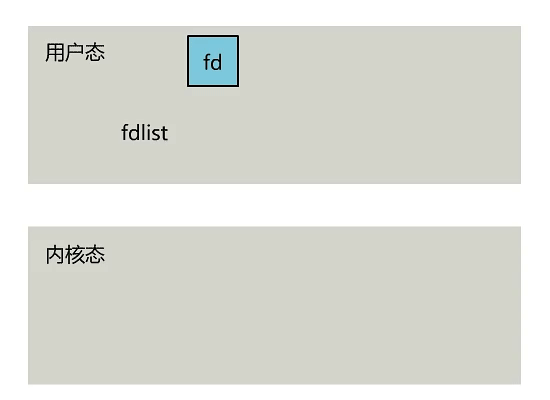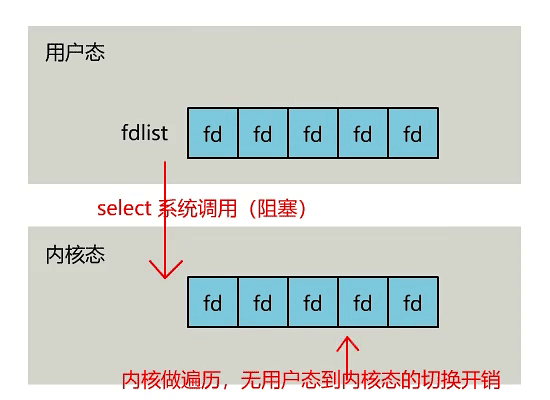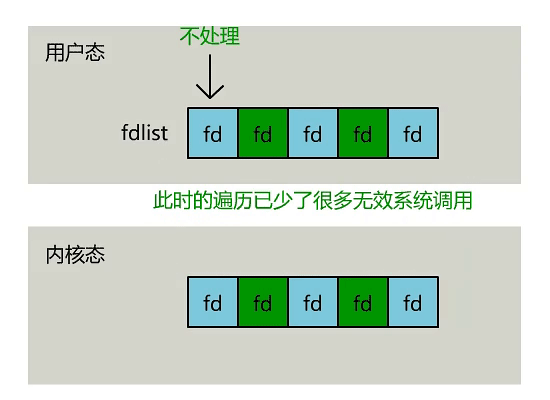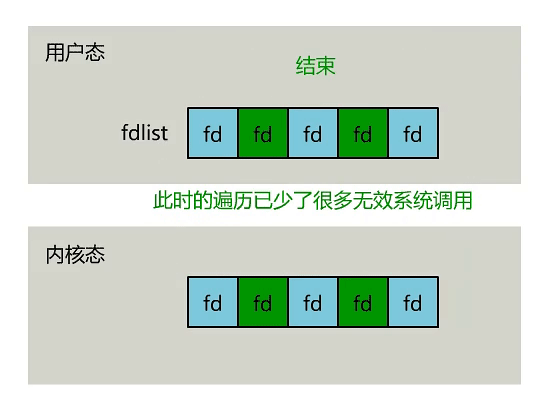
select 是操作系统提供的系统调用函数,通过它,可以把一个文件描述符的数组发给操作系统, 让操作系统去遍历,确定哪个文件描述符可以读写, 然后告诉我们去处理:
select 是操作系统提供的调用函数,通过这个函数可以把一组 fd 传给操作系统,操作系统遍历 fd,将完成准备的文件描述符个数返回给用户线程,用户线程再去逐个遍历 fd 查看哪个 fd 已经处于就绪的状态,然后再去处理。
select 的特点如下:
- 用户需要将监听的 fd list 传入到操作系统内核中,内核来完成遍历操作并将解决返回,这样在高并发场景数组的复制操作下会过多的消耗资源。select 的这一操作仅解决了系统的上下文切换的开销,遍历数组是依旧存在的。select 返回结果是就绪的 fd 个数,用户线程还需要判断哪个 fd 处于就绪状态。
- select 可以传入一组 socket 然后等待内核的处理结果,但是其 list 大小只有 1024 个,每次调用 select 都需要将 fd 数组从用户态复制到内核态,其开销比较大。调用 select 后返回的是就绪 fd 数量,还需要用户再次遍历。
针对 select 的缺点,poll 为了增加单次监听 socket 的个数,采用了链表的结构,放弃了数组的结构,但是其核心需要遍历的缺点依然没有解决。
针对 select 和 poll 的缺点,epoll 应运而生,其核心主要包括三个方法:
# 在内核开辟一个区域用来存放需要监听的fd
epoll_create
# 向内核中添加、修改、删除需要监控的fd
epoll_ctl
# 返回已经就绪的fd
epoll_wait
核心如下:
- 内核中存储了一份文件描述符 fd 的集合,无需用户每次都从用户态传入,只需要告诉内核修改的部分就可以。
- 内核中不再通过轮询的方式找到就绪的文件描述符 fd,而是通过异步 IO 事件进行唤醒。
- 内核会将有 IO 事件发生的文件描述符 fd 返回给用户,用户不需要自己进行遍历。
epoll 的数据操作有两种模式:水平模式 LT(level trigger)和边缘模式 ET(edge trigger)。LT 是 epoll 的默认操作模式
- LT 模式: epollwait 函数检测到有事件发生时需要通知应用程序,但是应用程序不一定及时进行处理,当 epollwait 函数再次检测到该事件的时还会通知应用程序,直到事件被处理。可以理解为 mq 发送消息的 at least once 模型。
- ET 模式:epollwait 函数检测到事件发生只会通知应用程序一次,后续 epollwait 函数将不再监控该事件。因此 ET 模式降低了同一个事件被 epoll 触发的次数,效率比 LT 模式高。可以理解为 mq 发送消息的 exactly once 模型。

IO 多路复用方式有 select,poll 以及 epoll,该函数都是内核层面的,从 BIO 的代码中可以看到 accept 函数,从之前的分析可以知道该方法是阻塞的,
Netty 实战
大家都可能注意到了,在实际的操作中 NIO 的代码是比较复杂的,Netty 就是对 NIO 做了包装,保证在实际操作中方便使用。 针对 Server 端的代码如下:
//Netty的Reactor线程池,初始化了一个NioEventLoop数组,用来处理I/O操作,如接受新的连接和读/写数据
EventLoopGroup boss = new NioEventLoopGroup(1);
EventLoopGroup work = new NioEventLoopGroup(8);
try {
//用于启动NIO服务
ServerBootstrap serverBoot = new ServerBootstrap();
serverBoot.group(boss, work)
//通过工厂方法设计模式实例化一个channel
.channel(NioServerSocketChannel.class)
//设置监听端口
.localAddress(new InetSocketAddress(port))
// 设置 server 端的一些参数项
.childOption(ChannelOption.CONNECT_TIMEOUT_MILLIS,30000)
.childOption(ChannelOption.MAX_MESSAGES_PER_READ,16)
.childOption(ChannelOption.WRITE_SPIN_COUNT,16)
// 设置监听的处理 channel initializer
.childHandler(new AppServerChannelInitializer());
//绑定服务器,该实例将提供有关IO操作的结果或状态的信息
ChannelFuture channelFuture = serverBoot.bind().sync();
System.out.println("在" + channelFuture.channel().localAddress() + "上开启监听");
//阻塞操作,closeFuture()开启了一个channel的监听器(这期间channel在进行各项工作),直到链路断开
channelFuture.channel().closeFuture().sync();
} catch (Exception e) {
log.error("encounter exception and detail is {}", e.getMessage());
} finally {
boss.shutdownGracefully().sync();//关闭EventLoopGroup并释放所有资源,包括所有创建的线程
work.shutdownGracefully().sync();//关闭EventLoopGroup并释放所有资源,包括所有创建的线程
}
一般情况下 IO 的压力都是在服务端,默认情况下客户端也是采用的 BIO,除非是在客户端也是需要提供服务。
// 配置相应的参数,提供连接到远端的方法
// I/O线程池
EventLoopGroup group = new NioEventLoopGroup();
try {
//客户端辅助启动类
Bootstrap bs = new Bootstrap();
bs.group(group)
//实例化一个Channel
.channel(NioSocketChannel.class)
.remoteAddress(new InetSocketAddress(host, port))
//通道初始化配置
.handler(new AppClientChannelInitializer());
//连接到远程节点;等待连接完成
ChannelFuture future = bs.connect().sync();
//发送消息到服务器端,编码格式是utf-8
future.channel().writeAndFlush(Unpooled.copiedBuffer("Hello World", CharsetUtil.UTF_8));
//阻塞操作,closeFuture()开启了一个channel的监听器(这期间channel在进行各项工作),直到链路断开
future.channel().closeFuture().sync();
} finally {
group.shutdownGracefully().sync();
}
总结
IO 从开始的瓶颈就是在操作系统的 read 数据读取方法,由于这个阻塞的方法导致了 BIO 的产生,为了解决阻塞 IO 的问题,同时提高效率,就产生了使用多线程技术操作 IO 来提升性能,但是 IO 的瓶颈问题并没有解决。后来操作系统做出了改变,提供了非阻塞的 read 函数,这样应用程序在发起调用后不需要等待解决,而是采用轮询的方式查询数据有没有准备好,这样相比 BIO 在同一时间内就可以完成更多的 fd 操作,这就是 NIO。但是在高并发的场景下,对文件描述符的遍历和读取带来了更多的轮询操作,额外增加的系统调用增加了 cpu 的负担,并没有带来期望的性能提升。
后来操作系统做出了改进,将遍历文描述符的操作放进了内核来实现,这就是 IO 多路复用技术。多路复用的技术分为三个函数, select、poll 和 epoll。 poll 解决了 select 单次传入文件描述符的限制,但是没有解决客户端遍历查询文件描述符的问题,epoll 的产生解决了这个问题,只是将数据准备好的 fd 返回给客户端,减少了客户端的遍历操作。IO 模型的演进也是根据应用的需求而升级,倒逼操作系统的内核增加更多的提升性能的操作。
 蜀ICP备20004578号
蜀ICP备20004578号