昨天有个朋友咨询一个问题,他通过NFS MOUNT了一个分布式文件系统,发现对这个文件系统df的时候经常hang死,他检查了一番系统,发现内存使用率很高,大部分物理内存都被cache占用了。他想通过分析cache中都有哪些数据,通过这个分析来确认cache占用率高和NFS hang之间是否存在关联关系。当时我的建议是首先不要把问题直接定位到OS内存上,如果系统不存在严重的SWAP,哪怕物理内存使用率达到98%,也是关系不大的。
实际上使用NFS文件系统,出现客户端hang死,或者df命令HANG死的情况并不少见,我这些年里也遇到过多次。我遇到的NFS hang死问题的原因也十分复杂,不过大多数都与NFS BUG、网络问题、系统资源消耗过高、IO负载过大等有关。
NFS客户端访问NFS文件hang住,一般来说有三种可能性,一种是客户端出现问题,第二种是服务端出现问题,第三种是客户端和服务端都存在问题。似乎这个总结有点太笼统了,也有点投机取巧,不过穷举法是我们在针对未知问题分析的最重要的方法。如果我们不能穷举所有的可能性,那么在问题诊断分析的时候就可能无法定位。在我多年的经验里,很多当时认为十分灵异的问题,都是因为我们以前的知识面不足,无法穷举到真正的故障路径。
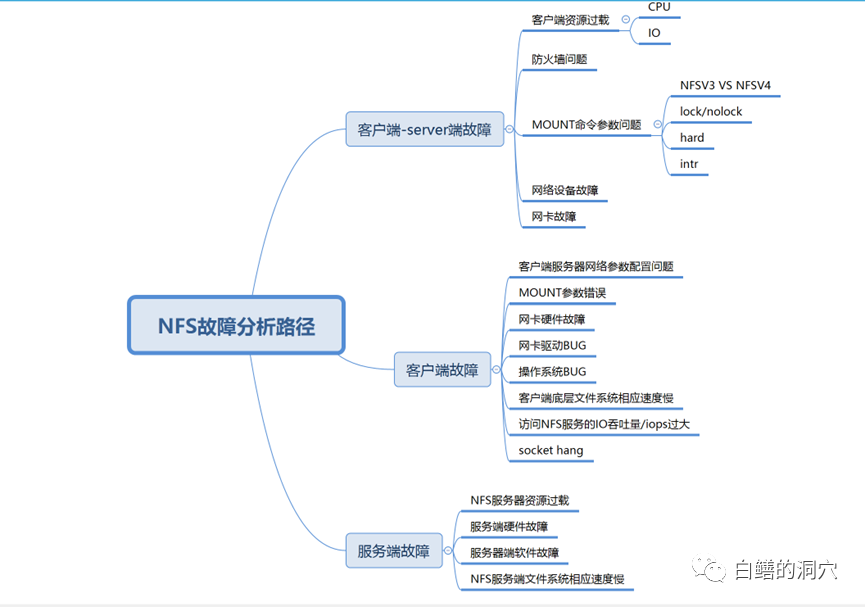
上面的思维导图是我这些年遇到过的一些NFS HANG的情况,其中遇见最多的还是和网络有关的,自从NFS V3/V4版本之后,NFS或者OS自身BUG导致的问题逐渐减少,而网络方面遇到的问题逐渐变多起来。特别是防火墙问题,最近五六年里,我遇到的大型系统中的NFS问题大部分和防火墙有关。随着企业对网络安全的要求越来越高,防火墙也不断地在调整策略,有时候有一条策略就会导致NFS的网络包被防火墙过滤,从而导致NFS的故障。五六年前我遇到过一个客户的NFS故障,只要访问一个文件NFS就会HANG死,访问其他文件就啥事没有。当时实在没办法了只能用网络抓包的方式去跟踪,最后发现客户最近上了一个敏感词过滤的策略,因为这个文件名带有敏感词汇,因此网络就丢包了。
实际上IP存储专网建设十分重要,关键系统使用NFS的时候一定要使用IP存储专网,最好不要经过防火墙,不过很多大企业对于跨机房访问的网络安全管理十分变态,防火墙是必须要经过的,一个NFS访问经过至少两个防火墙,一旦网络安全管理员与存储管理员之间没有很好的沟通,那么因为防火墙导致的NFS问题那就少不了了。另外我们以前遇到的大多数NFS故障场景都没有使用IPSAN专网,NFS使用的网络是和业务网混合使用的,业务网出现的任何问题,都会引起NFS文件系统的抖动,从而导致NFS服务不稳定。
是否Socket hang的问题可以通过netstat命令来看是不是存在大量的TCP连接处于CLOSEWAIT状态,如果存在这种情况,那么很可能你遇到了socket hang。Socket hang大多数和IO负载过高、客户端或者服务器端OS相应慢或者某个OS bug有关。也可能和TCP的keepalive参数设置有关。
另外一点是我们是用NFS的环境中,可能还安装了数据库服务器、中间件服务器等,这些系统要求调整OS的网络参数,而这些参数的调整很可能并不适合NFS服务。其中常见存在冲突的几个参数如下:
- lnet.ipv4.tcp_keepalive_time
- lnet.ipv4.tcp_keepalive_intvl
- lnet.ipv4.tcp_keepalive_probes
- lnet.ipv4.tcp_tw_recycle = 0
- lnet.ipv4.tcp_tw_reuse = 0
- lnet.ipv4.tcp_retries1 = 3
- lnet.ipv4.tcp_retries2 = 15
实际上NFS HANG的问题分析因为涉及的原因很多,所以往往还是不容易定位的,不过如果df命令hang,而且是可重现的,那么分析起来还是有方法的。最好的防范就是使用strace去跟踪df命令的堆栈。看看hang在什么地方,就比较容易定位问题了。
最后要说明的是,messages日志是一定要首要分析的,不管是客户端还是服务端的messages日志都应该尽早去看。虽然说很可能我们看到的只是NFS命令超时这类的比较笼统的信息。
 蜀ICP备20004578号
蜀ICP备20004578号