彻底理解操作系统:CPU与实模式
对于人类来说,我们不喜欢拐弯抹角,喜欢更直接的东西,“有话直说”、“没有中间商赚差价”、“简洁的设计”等等,然而对于计算机,尤其是对内存管理来说则恰恰相反,在这里”简洁”的设计往往不是好的设计,这到底是什么意思呢?
我们在很早的文章中就提到过,内存从本质上将非常简单,你可以将其想像成一个个的小盒子组成,每个小盒子要么能存储1要么存储0,每8个小盒子组成一个字节(8比特),每个字节都有一个唯一的地址,通过这个地址我们就能从相应的一组小盒子取出这个比特。
其它没了。
看到了吧,内存本身其实是非常简单的,然而程序员以及程序使用内存的方式又让这个问题变得复杂起来,分析任何复杂问题都要抓住重点、抓住核心问题,那么这里的重点以及核心是什么呢?不卖关子,这里的核心在于两个字:寻址,Addressing。一切都是围绕寻址展开的。
寻址,最重要的就是寻址
什么是寻址 Addressing?所谓寻址就是找到内存中某个我们需要的数据的方式。
哪怕以我们平时去储物柜取东西都有很多“寻址”方式:
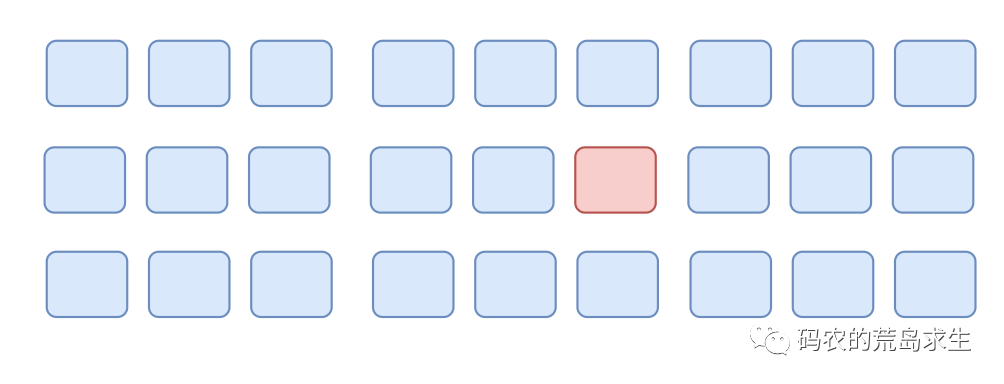
- 直接告诉我们一个编号,我们拿到这个编号后按个去找,就像下面这张图,我们需要找到东西在第15号储物柜中,那么我们根据15这个地址就能找到第15号储物柜。
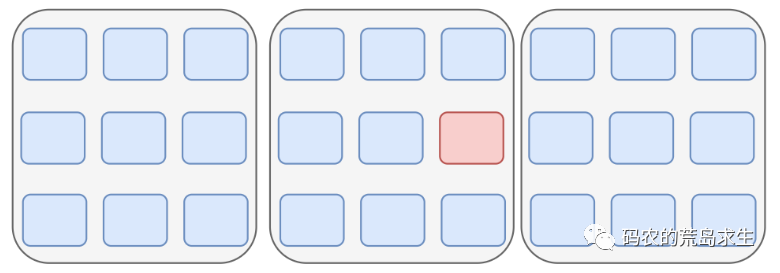
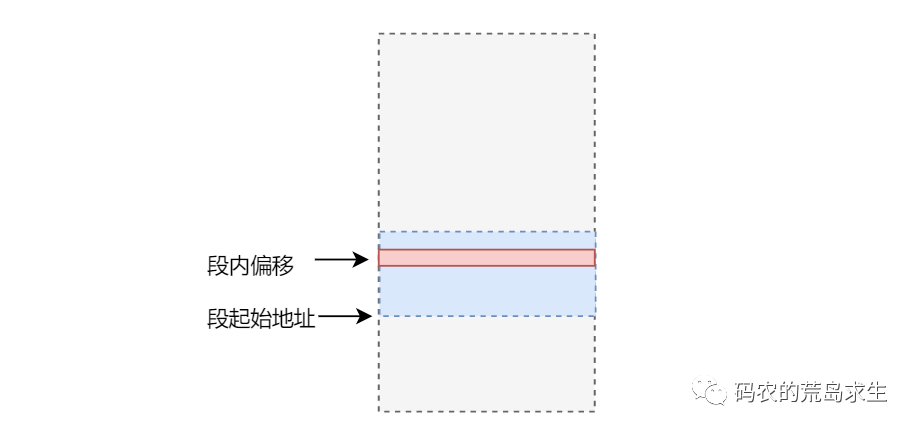
- 当然我们也可以将储物柜划分区域,还是以刚才的储物柜为例我们可以划分为3个区域,当我们需要找东西时告诉我们其在储物柜的哪个区域,以及在该区域中的”偏移”是多少。
以下图为例我们需要的东西在第二个区域,区域内的偏移为6(该区域中的第6个储物柜)。
实际上,第一种更像是“绝对寻址”,什么意思呢?就是找到某个具体的储物柜是根据一个“写死的地址”(hardcode),很死板,第二种更像是相对寻址,稍显灵活一些。怎么样,你是不是感觉这两种其实也没什么区别嘛,的确,对于找储物柜这个例子来说这两种方式的确没什么区别,但对于内存来说就不太一样了。
死板 vs 灵活
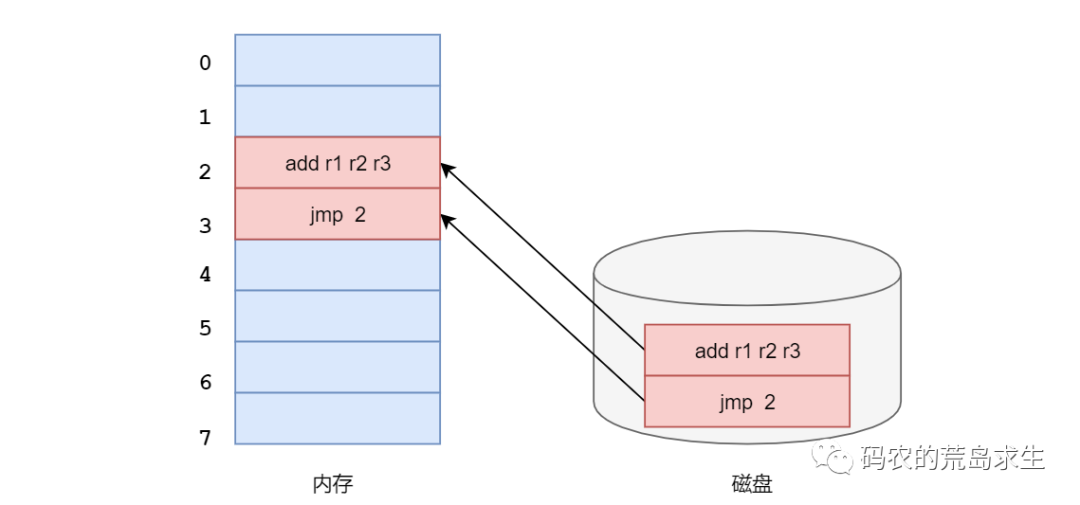
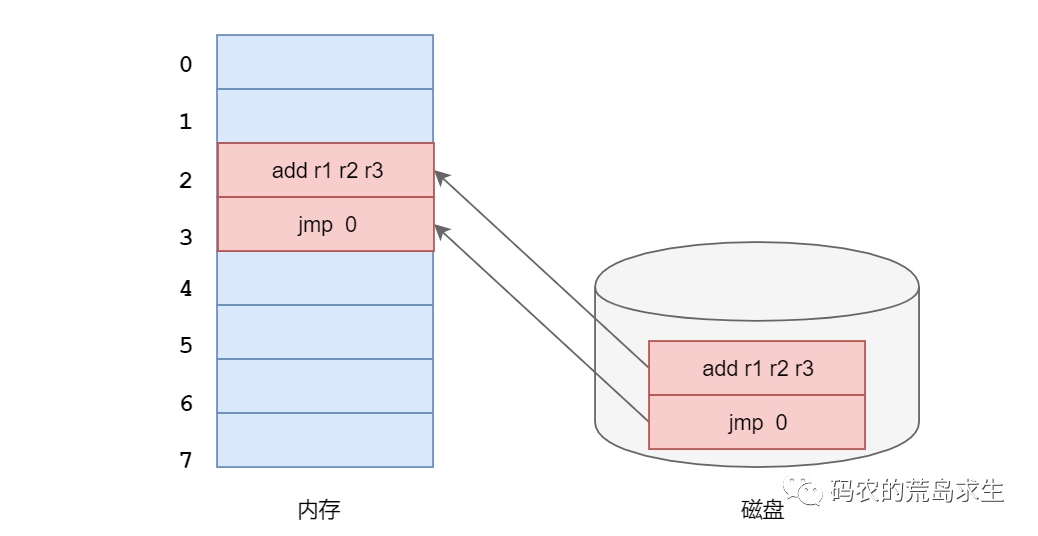
我们知道程序以及程序使用的数据编译好后存放在磁盘上,运行时要加载到内存中,因此这里同样存在寻址问题:我们需要根据内存地址找到机器指令以及数据,接下来假设有一个只有8字节大小的内存和一个只有2字节机器指令的程序(无需关心实际意义):

这段2字节的代码非常简单,其实就是一个无意义的while循环,注意看这里的jmp这条指令,我们直接跳转到内存地址2,这就是一个写死(hard
code)的内存地址,这就意味着我们必须把该程序加载到内存地址为2的位置上:
否则这段指令根本没有办法运行,比如我们把这段代码加载到内存地址6上去:
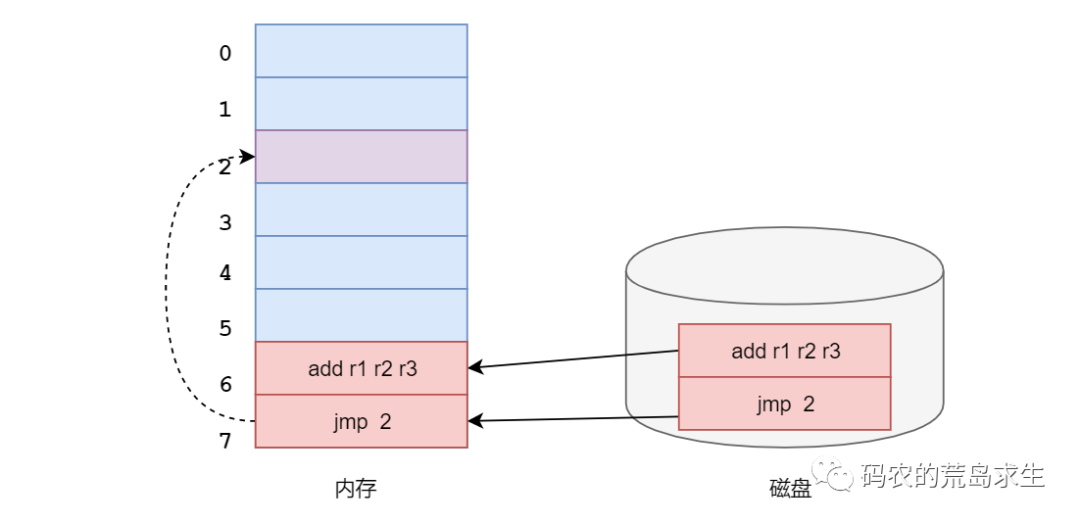
那么在执行jmp 2时我们根本没有办法跳转到add这行指令,有的同学可能觉得无所谓,不就是内存地址写死了嘛,好像也没什么大不了的吧。
如果一次只能运行一个程序的确也没什么大不了的,但对于操作系统最核心的功能之一:多任务,也就是一次可以运行多个程序来说这个方案简直行不通。
在这种方案下你几乎没有办法一次运行多个程序,除非在运行之前你给要运行的这几个程序划定好区域,比如要运行两个程序A和B,A占用0~3这个区域的内存;B占用4~6这个区域的内存,对于现代程序员来说你能想象在程序运行之前就需要给它划定好区域吗?显然,这非常繁琐,也容易出错。
如果你在上世纪六七十年代写代码,面临的大概就是这样一种状况。实际上这个问题的核心就在于重定位,程序使用的地址不能绑定在一个内存区域上,需要足够灵活,我们需要在不修改代码的情况下把程序加载到任意内存区域上运行!想一想该怎么解决这个问题。
作为程序员肯定和文件路径打过交道,如果你能明白绝对路径与相对路径就能解决重定位问题。
绝对路径与相对路径
想一想绝对地址有什么问题?这个问题就好比你在程序中读取一个绝对地址时:
/user/xiaofeng/doc/a.c
如果是你自己的计算机那么没有问题,但如果这个程序在其它人的计算机上运行就不一定了,因为其它人的计算机中不一定有这个路径,这时该怎么办呢?聪明的你一定知道,那就不要使用绝对路径,而是使用相对路径就可了:
./a.c
其中./表示程序运行时所在的路径,这时不管这个程序在哪个路径下运行都能找到a.c这个文件,这时所在的目录就成为了基准。
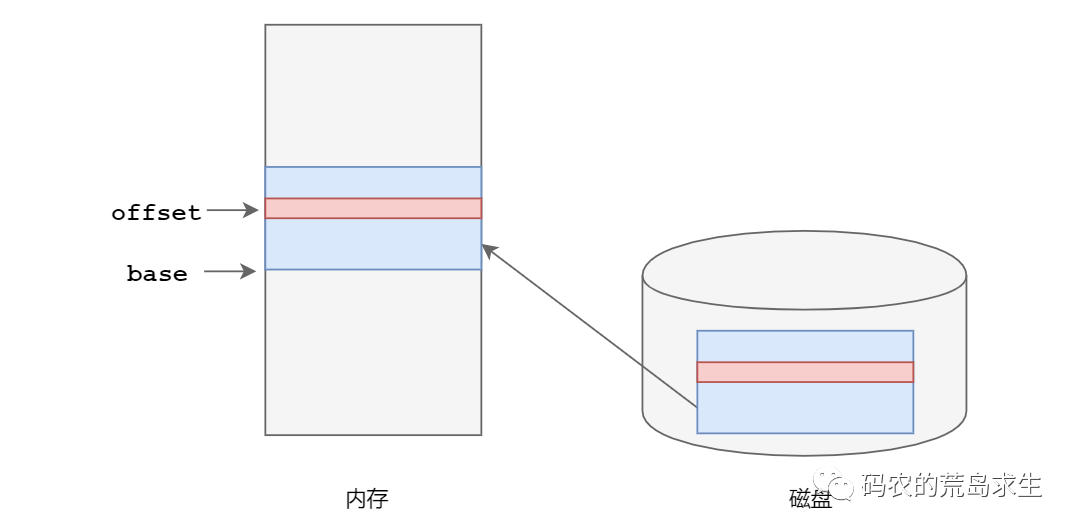
解决重定位这个问题也是同样的道理,编程生成可执行程序时不再使用绝对内存地址,而是使用相对地址,怎么使用相对地址呢?相对于谁呢?很简单,相对于该程序被加载到的内存起始地址。
此时我们的jmp命令后面不再是一个绝对的内存地址,而是一个相对地址:0,但毕竟向内存发出读写指令时必须使用一个内存地址,那么CPU执行jmp 0时该怎样将其转为一个内存地址呢?
很简单,因为这一段程序被加载到了内存起始地址2,因此只需要用相对地址加上起始地址得到的就是真实的物理内存地址:
- 物理地址 = 起始地址 + 相对地址
很简单吧,这样不管这段程序被加载到了哪个内存区域,只要我们知道起始地址那么总能计算出真实的物理内存地址,重定位问题就可以这样解决。实际上你会发现,这个储物柜的第二种寻址方式也没有什么区别。
分段式内存管理
我们知道,程序的内存从内容上可以分为存放机器指令的代码区域、存放全局变量的数据区域、保存函数运行时信息的栈区等,显然我们可以将程序按照这种划分进行分段管理,段内使用相对地址,这样无论这些段被加载到内存的哪个区域我们都能方便的计算出正确的物理内存地址。
我们将各个段在内存中的起始地址放到专用的寄存器中,X86 CPU中有这样几个段寄存器,CS、DS、SS以及ES,这些寄存器有什么用呢?这几个寄存器就用来存放各个段在内存中的起始地址(暂且这样理解,稍后你会发现这些寄存器的真实用法):
- 保存机器指令的区域,这个区域就是我们所说的代码段(Code Segment),因此我们可以使用一个寄存器来专门指向代码段,这就是CS寄存器的作用,CS也是Code Segment的缩写。
- 同样的道理,程序运行起来后还有专门的区域用来保存数据,因此必须要专门的寄存器指向数据段(Data Segment),这就是DS寄存器的作用,DS是Data Segment的缩写。
- 程序运行起来后还有运行时栈(Stack Segment),因此可以使用SS寄存器来指向程序员运行时栈,SS是Stack Segment的缩写。
- 此外还有ES寄存器,Extra Segment,其用作临时段寄存器。
除了内存分段管理之外,我们的程序可以读写任意内存区域,有的同学可能不以为意,这又能怎样呢?
没有内存保护会怎样?
至今,在多线程编程中这个问题依然困扰着程序员,因为同一个进程中的线程共享同一个地址空间,这也就意味着你的线程可以修改地址空间中任何可写的区域,包括栈区以及堆区,当然这也就意味着其它线程可以修改你的线程使用的数据,这是多线程中一大类bug的来源。
而这个问题在内存地址没有任何保护情况下更加严重,因为这时不是一个进程而是多有进程包括操作系统都共享同一个物理内存地址,任何一个进程都可以修改内存中任何位置,你的进程可以破坏其他进程使用的内存,可以破坏操作系统使用的内存,破坏其它进程大不了重新启动这个进程,但是如果破坏了操作系统那么没有办法,此时你只能重新启动计算机,如果CPU没有提供内存保护机制,那么操作系统连自己都保护不了更何况去保护其它进程。
没想到吧,看似简单直接的内存读写竟然会有这么多问题。
实模式
好啦,到目前为止让我们暂且总结一下。
- 绝对的内存地址不好用,这样的地址必须将程序加载到内存的特定位置上,为解决这个问题使用相对地址,x86中为每个程序的区域都配备有专用的寄存器用来存放该段在内存中的起始地址,这样就可以根据基址加偏移计算出物理内存地址,注意,这里计算出来的是真实的物理内存地址。
- 内存读写没有任何保护,程序可以读写内存的任何区域。
实际上这就是早前内存管理的模式,非常直接非常原始,x86 CPU将这种原始的内存管理方法称之为实模式,real mode,这种模式也被称之为 real address mode,顾名思义,我们在程序中看到的都是真实的物理内存地址。

原来,早期的x86 CPU能访问的最大内存被限制在1MB(2^20 byte),你可能会想这可用内存也太少了吧,对于当今程序员或者用户来说1MB几乎什么都干不了,哪怕都存不下一首歌,然而在上世纪80年代,1MB内存是一片极为广阔的空间,以至于比尔盖茨在上世纪80年代说过:640k ought to be enough for anyone,对大部分人来说640K内存已经足够用了。

除此之外,更加捉襟见肘的是早期x86 CPU寄存器只有16位,16位寄存器是没有办法访问整个1MB内存的,16位寄存器最多能访问64K大小的内存,要想访问1MB内存那么内存地址就需要20位,而寄存器本身就16位,因此根本装不下,怎么办呢?
很简单,一个寄存器不够我们就用两个,第一个寄存器被叫做selector,说白了其实存放的是储物柜区域的编号,因此也叫做段寄存器, segment register,管叫做区域还是叫做段本质上没啥区别。
第二个寄存器被叫做offset,说白了就是区域内的编号或者叫做区域内的偏移,这样真正的内存地址就由两部分组成 selector:offset,此时内存地址的计算方式是这样的:
- 16 ∗ selector + offset
此时给定一个段寄存器再给出一个偏移我们就能直接在内存中找到需要的数据:
因此这里计算出来的内存地址就是物理内存地址。此外,在实模式下CPU不提供内存保护机制,程序可以随意读写任何内存区域,哪怕是操作系统所在的区域其它程序也可以读写。现在可以总结下早期x86处理器的特点了:
- 寻址空间有限,只有1MB
- 利用 selector:offset的方式利用两个16位寄存器来寻址1MB内存
- 没有内存保护机制,当然,没有内存保护机制的一大优点就在于内存读写速度要更快,原因就在于不需要经过虚拟内存地址到物理内存地址的转换,也不需要进行任何检查(这可能是实模式下仅有的优点)
在80286之前,所有x86 CPU都运行在实模式下,而为了后向兼容,即使是现代x86在重置(加电时)后也会首先进入实模式,后续才会跳转到保护模式(protected mode),关于保护模式我们在后续文章中讲解。
实模式与操作系统
实模式是x86系列处理器最早期的内存管理模式,这一时期的操作系统别无选择,只能运行在这种模式下,早期的DOS系统以及早期的Microsoft
Windows操作系统就运行在实模式下。虽然实模式理解起来很简单,但这种模式最主要的问题在于:
- 把物理内存暴露给程序
- 没有内存保护机制
这两者结合起来的后果就是程序不被受限,程序员都知道,我们写的代码充满了bug,在现代操作系统中程序很容易把自己搞挂,而在早期的操作系统中程序就会很容易的把整个系统搞挂,为解决这一问题,x86 CPU在80286开始引入保护模式,后续文章会有详细讲解。
尽管现代操作系统(Windows、Linux)等早已不运行在实模式下,然而实模式却依然保留了下来,你可能会想为什么x86 CPU依然需要保留实模式呢?
我们都知道代码有屎山一说,其实对于历史悠久的x86来说也有类似的问题。
CPU这种硬件和软件一样也是在不断演变进化的,从16位实模式演进到了32位保护模式以及现代的64位处理器,但早期程序员围绕着16位实模式的x86CPU编写了很多软件,当CPU发展到32位保护模式时之前的基于16位实模式编写的软件该怎么办?不支持了吗?不支持的话只有两种可能:1) 用户不再购买不兼容16位软件的CPU 2) 重写代码,以程序员的尿性来说大概率不会重写,intel也非常识时务,因此在后来的32位乃至现代的64位处理器上依然保留了实模式,x86系列处理器在重置时会首先进入实模式,对于不使用实模式的现代操作系统来说简单的初始化工作后会跳转到保护模式。
因此我们可以看到,实模式就像原始的进化基因一样依然存在,就像动物胚胎有腮一样,只不过该过程一闪而过,实模式也是在计算机启动阶段快速闪现,这种古老的内存管理方式依然留下了自己的烙印。
总结
实模式是一种非常古老的内存管理方式,在这种方法下程序员直面物理内存,且处理器没有提供内存读写机制,程序员可读写任何内存区域。
实际上实模式对于现代操作系统来几乎没什么用处,只不过如果你针对x86 CPU编写操作系统那么实模式是必须要了解的,但对于其它CPU来说则没有这样的历史包袱,因此有很多操作系统教材开始基于非X86平台来讲解,这样能更快速的讲解操作系统而不是在一上来就在各种内存模式中打转。
注意,本文提到的实模式仅仅针对x86系列处理器而言,对于上层应用的大部分程序员来说根本就不需要关心实模式,然而技术就和生物一样也在不断演变进化,了解过去才能更好的理解当下以及未来。
 蜀ICP备20004578号
蜀ICP备20004578号