Kubernetes 集群高可用代理实践之路
前言
在 Kubernetes 集群的 高可用拓扑选项[1] 中,介绍了集群高可用的两个方案:
- 使用堆叠(stacked)控制平面节点,其中 etcd 节点与控制平面节点共存
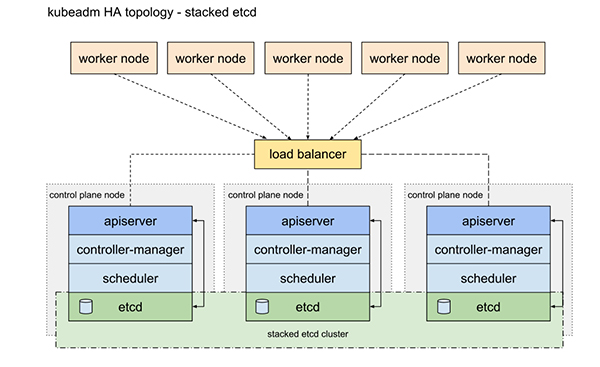
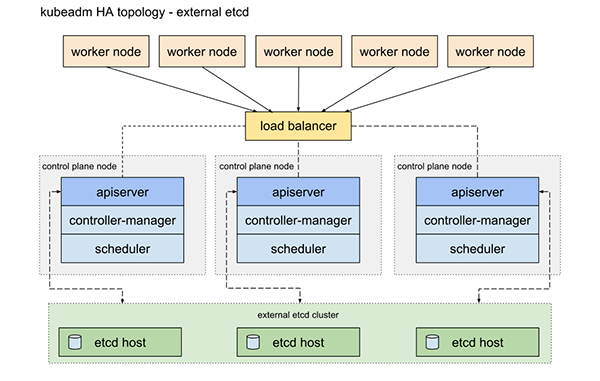
- 使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行
我们知道实现高可用架构的本质就是在做冗余 。
对于 Kubernetes 集群的高可用架构:
- 应用层:Pod 的高可用性由 Kubernetes 自行保证。主要通过健康检查和重启策略实现 Pod 的故障自我修复能力,通过调度算法实现 Pod 分布式部署,通过副本数监控机制,保障 Pod 的实时运行副本。
- worker node :工作节点负责运行工作负载,可以任意横向扩展,随时加入新节点,不需要考虑高可用架构。
- etcd :作为集群状态信息存储组件,可组建 etcd 集群方式实现高可用,对于 Kubernetes 集群有 stacked etcd 和 external etcd 两种方案。
- control plane node :控制平面节点即 master 节点,负责与工作节点上的 kubelet 和 kube-proxy 进行通信来维护整个集群的健康工作状态。
其中控制平面节点的三个核心组件:
- kube-controller-manager 和 kube-scheduler :只要部署多 master 实例,即可通过自身选举机制实现高可用。
- kube-apiserver :apiserver 服务器是无状态的,负责提供 Kubernetes 的 API 服务,是整个集群控制的入口。
可见,kube-apiserver 的高可用性将决定整个集群的高可用(etcd 高可用同样极其重要,但不在本文探讨范围内)。
由于 apiserver 本质上是一个无状态的 HTTP API 服务,因此,实现 apiserver 的高可用性,本质上就是实现 web 服务器的高可用性,可以通过为其增加可水平扩容的负载均衡器(load balancer ,简称 lb )。
后续用户( kubectl 、 dashbaord 等其他客户端)和集群内部的组件都将通过访问 lb 来访问 apiserver 。
这下问题就变成了 如何实现 lb 的高可用。
先来看 lb 的选型,可以采用硬件负载均衡(F5),这是最好但也是最昂贵的做法:

也可以使用代理软件(nginx/haproxy 等[2]),采用软件负载均衡的做法:
今天本文的分享内容便是对代理软件高可用的实践。
代理软件
对于代理软件的选型,可以根据实际需求决定,不会影响本文的高可用实践(目前对于集群代理主流使用的是 haproxy )。
本文将以 nginx 为例,并使用 Docker 部署:
$ docker run --name nginx -d -v $PWD/default.conf:/etc/nginx/conf.d/default.conf -p 80:80 nginx
对应的 default.conf 配置示例如下:
upstream cluster {
server 192.168.19.160:8080;
server 192.168.19.160:8081;
server 192.168.19.160:8082;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://cluster;
}
}
为了方便我们后续的测试,其中代理的三个后端服务是我们模拟的三个 web 服务(实际使用时替换为集群 apiserver 即可)。
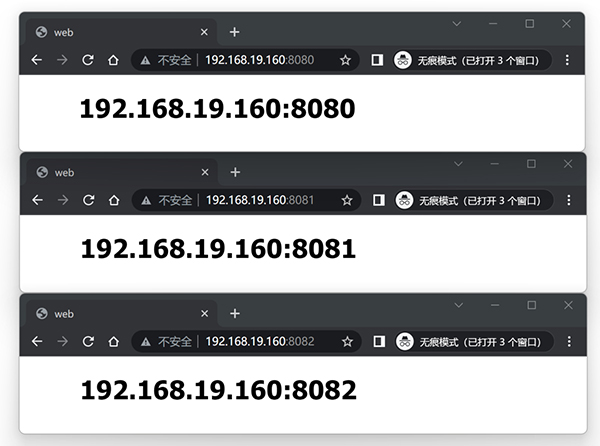
高可用的核心也是第一步就是 冗余 ,为了提升代理服务器的高可用,我们需要冗余一个实例,按照刚才的教程需要在主机 lb1 和 lb2 同时部署 nginx (也就是说有两台机子运行着 nginx 代理):
|
IP |
主机名 |
代理端口 |
默认主从 |
|
192.168.19.158 |
lb1 |
80 |
MASTER |
|
192.168.19.159 |
lb2 |
80 |
BACKUP |
测试这两个代理服务器,请求将会均衡到三个后端服务中的任意一个。
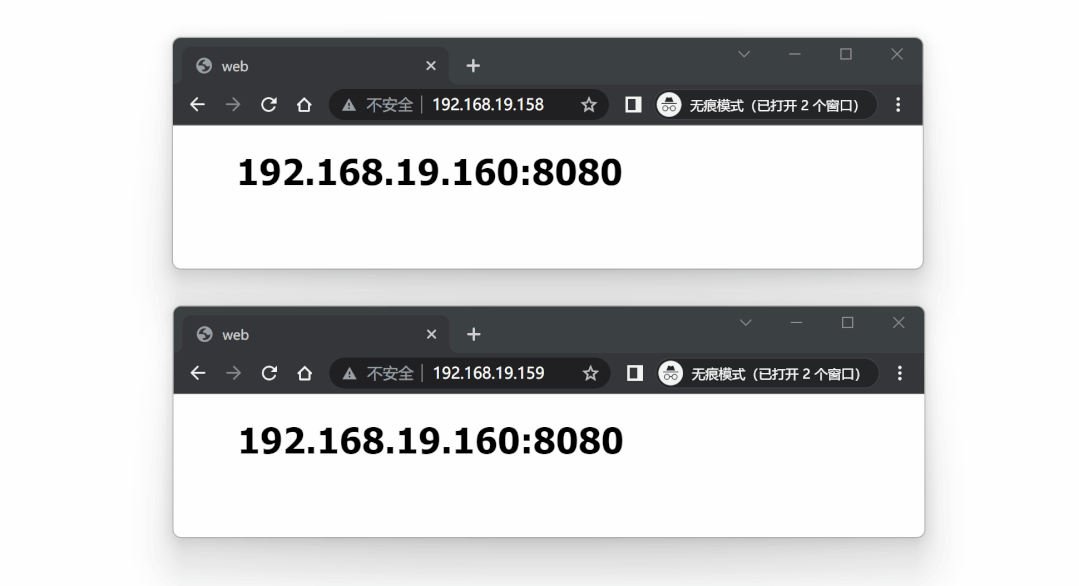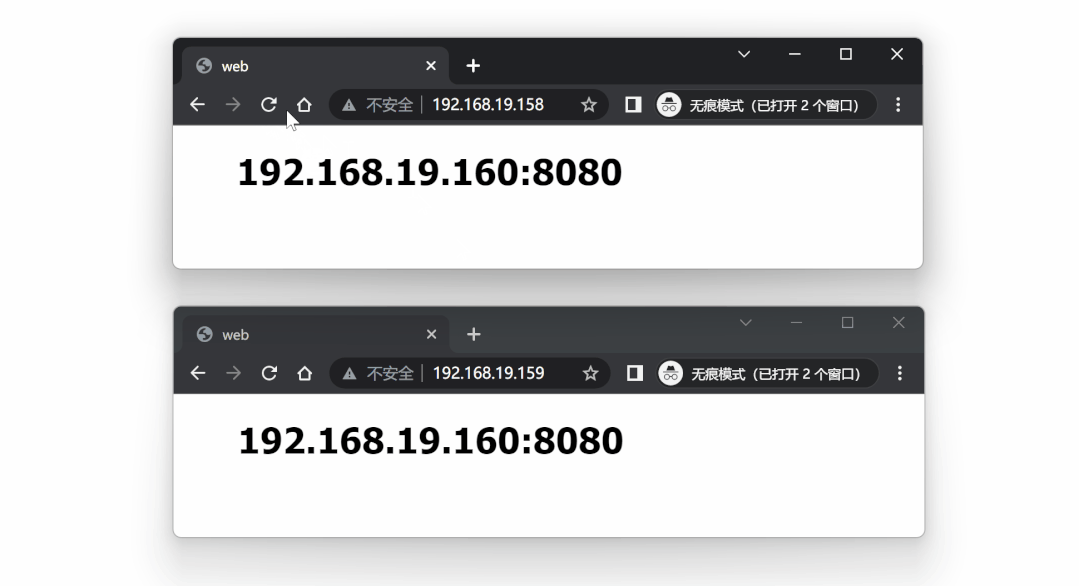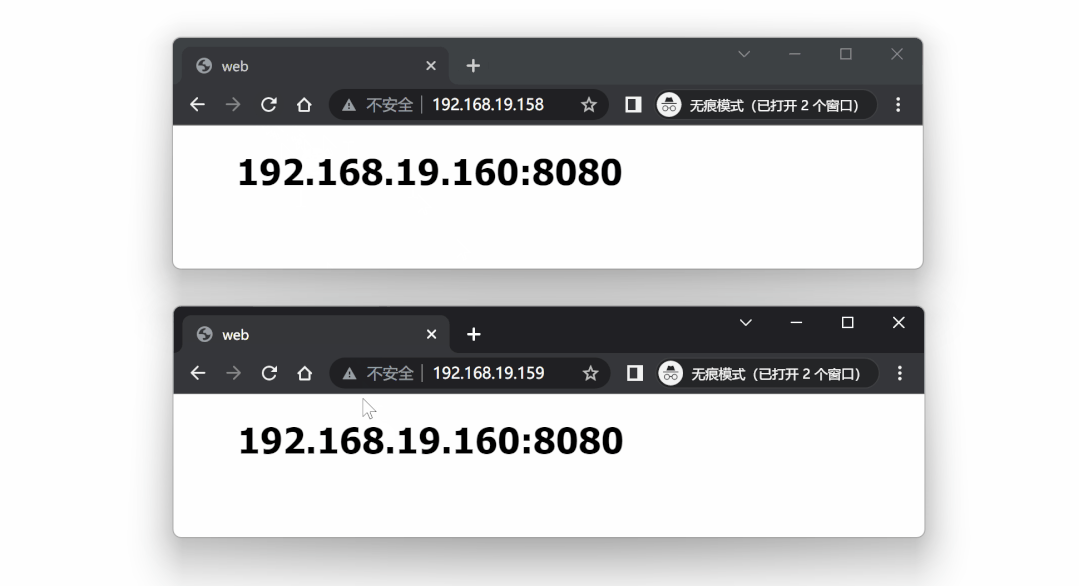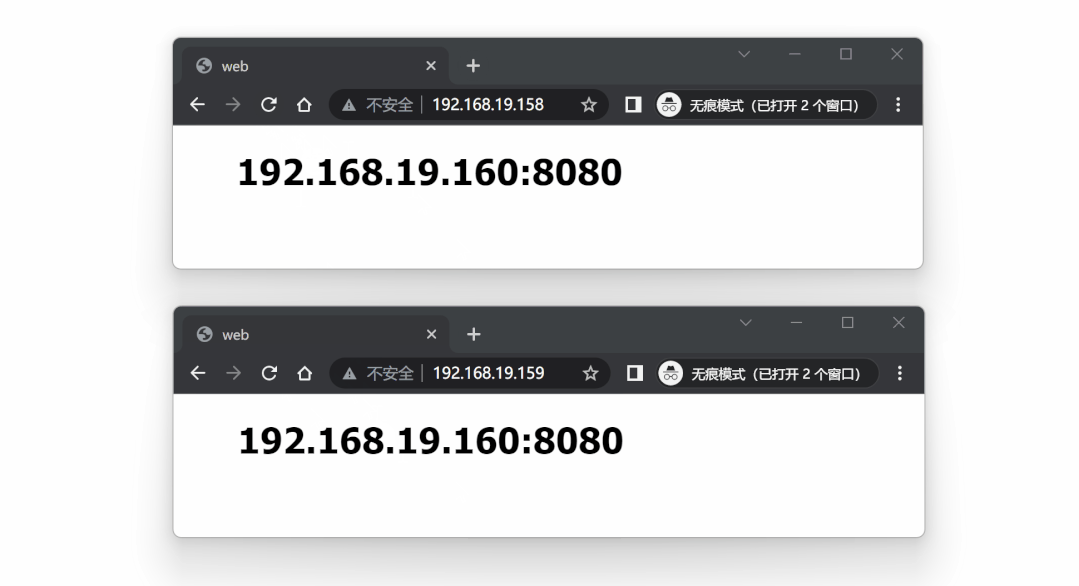
代理测试
接下来就该考虑如何实现服务器的自动故障转移,即 lb1 挂了之后,冗余的 lb2 如何快速顶上来使用,这一功能也称作:双机热备 。
双机热备

一图秒懂双机热备[3]
所谓双机热备,即主机和从机通过 TCP/IP 网络连接,正常情况下主机处于工作状态,从机处于监视状态,一旦从机发现主机异常,从机将会在很短的时间之内代替主机,完全实现主机的功能。
我们现在的需求很明确,即 lb1 作为主代理服务器提供给外部访问,lb2 作为从代理服务器,一旦 lb1 发生故障,lb2 可以立即顶替上去,以实现代理的高可用。
lb1 和 lb2 是不同主机,不同 IP 的,而我们又必须对外部访问端透明,只能有一个 IP 给到外部。
只给外部一个 IP ,这个 IP 能不能正常情况下属于 lb1 节点,当 lb1 节点挂了之后又变成属于 lb2 节点的呢。
这就引出了 Virtual IP (虚拟 IP,简称 VIP )的概念了。
我们可以创建一个 VIP 为 192.168.19.200 ,正常情况下,该 VIP 绑定到 lb1 上,一旦 lb1 发生故障,VIP 立即漂移到 lb2 。对于外部访问端,就只需要调用 192.168.19.200 这个 VIP 就可以了,无需理会代理服务器究竟是 lb1 还是 lb2 。
这个 VIP 的漂移机制实现也有现成的工具:keepalived 。
keepalived
keepalived 是一个基于 VRRP 协议实现的 Web 服务高可用方案,可以利用其避免单点故障。
可以在 lb1 节点部署 keepalived 作为主服务器(MASTER),在 lb2 节点部署 keepalived 作为备服务器(BACKUP),对外表现为一个 VIP (默认绑定在 MASTER 所在节点)。
keepalived MASTER 会发送特定消息给 keepalived BACKUP ,当 BACKUP 收不到消息时(即 MASTER 宕机或发生故障), BACKUP 就会接管 VIP 。
- keepalived 需要注意脑裂问题的发生,即:MASTER 和 BACKUP 同时占用了 VIP
接下来我们就利用 keepalived 来实现 双机热备 机制以保障代理的高可用。
- 本文实验机环境:CentOS Linux release 7.9.2009 (Core)
在 lb1 和 lb2 节点都部署上 keepalived :
[root@lb1 ~]# yum -y install keepalived
[root@lb2 ~]# yum -y install keepalived
lb1 节点修改 keepalived 的配置文件:
[root@lb1 ~]# cd /etc/keepalived/
[root@lb1 keepalived]# pwd
/etc/keepalived
[root@lb1 keepalived]# vi keepalived.conf
lb1 节点 keepalived.conf 内容如下:
! Configuration File for keepalived
global_defs {
# # 通知邮件服务器的配置
# notification_email {
# # 当 master 失去 VIP 的时候,会发一封通知邮件到 your-email@qq.com
# your-email@qq.com
# }
# # 发件人信息
# notification_email_from keepalived@qq.com
# # 邮件服务器地址
# smtp_server 127.0.0.1
# # 邮件服务器超时时间
# smtp_connect_timeout 30
# 唯一 id ,通常设置为 hostname
router_id lb1
}
# 检查nginx是否存活
vrrp_script check_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2 # 检测时间间隔
weight -20 # 检测失败(脚本返回非0)则权重 -20
}
# 定义虚拟路由,VI_1 为虚拟路由的自定义标识符
vrrp_instance VI_1 {
state MASTER # 主节点为 MASTER ,备份节点为 BACKUP
priority 100 # 节点优先级,MASTER 比 BACKUP 高
interface ens33 # 绑定虚拟 IP 的网络接口
virtual_router_id 101 # 虚拟路由的 id ,两个节点设置必须一样
advert_int 1 # 心跳报文发送间隔,默认 1s
# 默认组播模式下,keepalived 所有的信息都会向 224.0.0.18 的组播地址发送,产生众多的无用信息,并且可能会产生干扰和冲突
# 可以使用单播模式,这是一种安全的方法,避免局域网内有大量的 keepalived 造成虚拟路由 id 的冲突
unicast_src_ip 192.168.19.158 # 配置单播的源地址,本机 IP
unicast_peer {
192.168.19.159 # 配置单播的目标地址,其它 IP
}
# 设置验证信息,两个节点必须一致
authentication {
auth_type PASS
auth_pass 123456
}
track_script {
check_nginx # 执行 Nginx 监控的服务
}
# 虚拟 IP 池, 两个节点设置必须一样
virtual_ipaddress {
192.168.19.200 # 虚拟 ip,可以定义多个
}
}
同样的步骤,修改 lb2 节点的 keepalived.conf 内容为:
[root@lb2 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
# # 通知邮件服务器的配置
# notification_email {
# # 当 master 失去 VIP 的时候,会发一封通知邮件到 your-email@qq.com
# your-email@qq.com
# }
# # 发件人信息
# notification_email_from keepalived@qq.com
# # 邮件服务器地址
# smtp_server 127.0.0.1
# # 邮件服务器超时时间
# smtp_connect_timeout 30
# 唯一 id ,通常设置为 hostname
router_id lb2
}
# 检查nginx是否存活
vrrp_script check_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2 # 检测时间间隔
weight -20 # 检测失败(脚本返回非0)则权重 -20
}
# 定义虚拟路由,VI_1 为虚拟路由的自定义标识符
vrrp_instance VI_1 {
state BACKUP # 主节点为 MASTER ,备份节点为 BACKUP
priority 50 # 节点优先级,MASTER 比 BACKUP 高
interface ens33 # 绑定虚拟 IP 的网络接口
virtual_router_id 101 # 虚拟路由的 id ,两个节点设置必须一样
advert_int 1 # 心跳报文发送间隔,默认 1s
# 默认组播模式下,keepalived 所有的信息都会向 224.0.0.18 的组播地址发送,产生众多的无用信息,并且可能会产生干扰和冲突
# 可以使用单播模式,这是一种安全的方法,避免局域网内有大量的 keepalived 造成虚拟路由 id 的冲突
unicast_src_ip 192.168.19.159 # 配置单播的源地址,本机 IP
unicast_peer {
192.168.19.158 # 配置单播的目标地址,其它 IP
}
# 设置验证信息,两个节点必须一致
authentication {
auth_type PASS
auth_pass 123456
}
track_script {
check_nginx # 执行 Nginx 监控的服务
}
# 虚拟 IP 池, 两个节点设置必须一样
virtual_ipaddress {
192.168.19.200 # 虚拟 ip,可以定义多个
}
}
[root@lb2 keepalived]#
在 global_defs 全局配置中,可以配置邮件通知,一旦 VIP 发生漂移(意味着主代理服务器发生了故障)就会发送邮箱通知我们去解决修复,而此时因为还有备代理服务器可以使用,不至于服务对外不可用。
整个配置的核心是在 vrrp_instance 虚拟路由的定义上,interface 指定绑定的网卡(节点 IP 所在的网卡);keepalived 默认为组播模式,我们为其更改为了单播;virtual_ipaddress 定义了需要生成的 VIP 列表(指定了 192.168.19.200)。
而 track_script 则是我们 VIP 漂移得以正常运作的关键,我们设定了每 2s 就去执行一次 /etc/keepalived/nginx_check.sh 脚本:
#!/bin/bash
if [ `ps -C nginx --no-header |wc -l` -eq 0 ];then
killall keepalived
fi
脚本实际就是检测代理软件(nginx)是否存活,如果挂了,就执行 killall keepalived 将自身停止,相当于将 VIP 让位给备服务器。
- 通常脚本里还会尝试重启一下代理软件,如果重启失败,再考虑执行 kill
先给脚本执行权限,然后启动 lb1 的 keepalived 服务:
[root@lb1 keepalived]# ls
keepalived.conf nginx_check.sh
[root@lb1 keepalived]# chmod 744 nginx_check.sh
[root@lb1 keepalived]# systemctl start keepalived
[root@lb1 keepalived]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.19.158/24 brd 192.168.19.255 scope global noprefixroute dynamic ens33
inet 192.168.19.200/32 scope global ens33
[root@lb1 keepalived]#
启动 lb2 的 keepalived 服务:
[root@lb2 keepalived]# ls
keepalived.conf nginx_check.sh
[root@lb2 keepalived]# chmod 744 nginx_check.sh
[root@lb2 keepalived]# systemctl start keepalived
[root@lb2 keepalived]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.19.159/24 brd 192.168.19.255 scope global noprefixroute dynamic ens33
[root@lb2 keepalived]#
可以从 ip a 命令看到,当前 VIP 192.168.19.200 位于 lb1 节点上。
此时访问 VIP 192.168.19.200 ,相当于访问 lb1 节点:
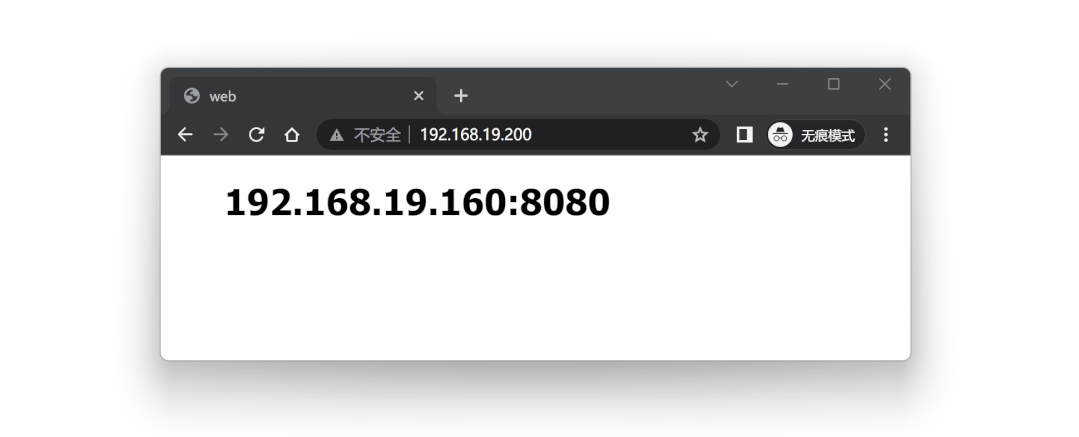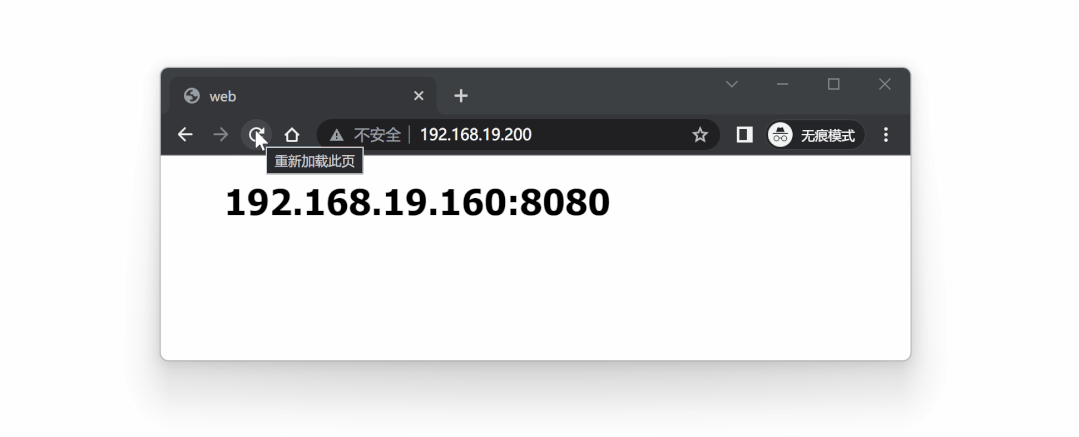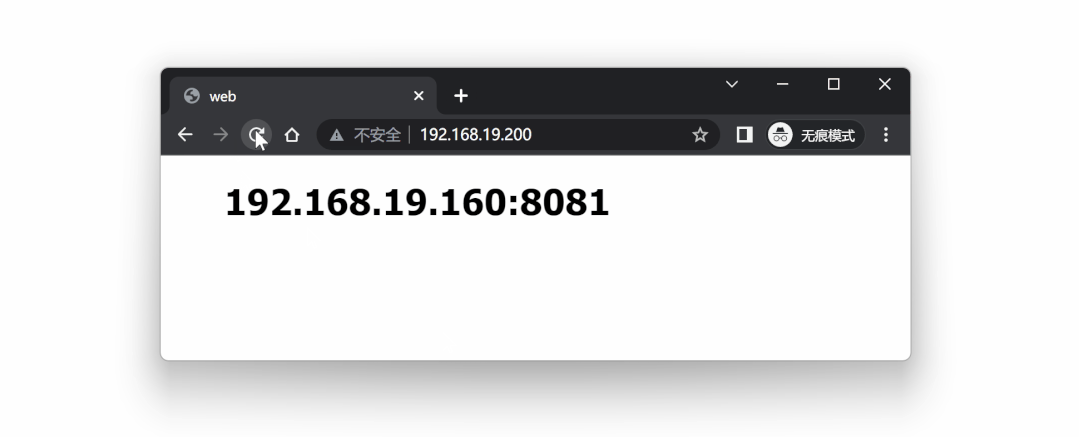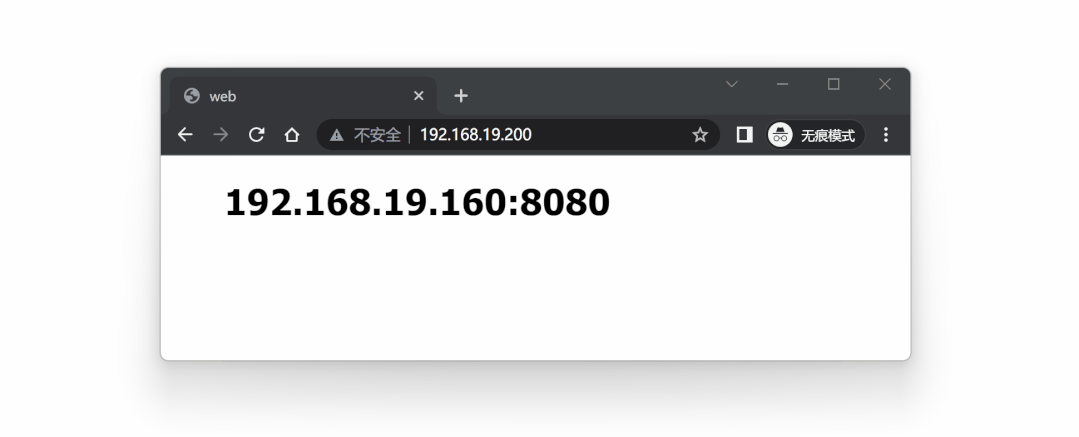
接着模拟故障,模拟当 lb1 代理服务挂掉后,lb2 能不能顶替上来使用,我们可以手动停止 lb1 节点的 nginx :
[root@lb1 keepalived]# docker stop nginx
nginx
[root@lb1 keepalived]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.19.158/24 brd 192.168.19.255 scope global noprefixroute dynamic ens33
[root@lb1 keepalived]#
此时发现,lb1 已经失去了 VIP 192.168.19.200 ,继续看 lb2 :
[root@lb2 keepalived]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.19.159/24 brd 192.168.19.255 scope global noprefixroute dynamic ens33
inet 192.168.19.200/32 scope global ens33
[root@lb2 keepalived]#
和预期一致,VIP 192.168.19.200 漂移到了 lb2 节点上。
再次访问 VIP 192.168.19.200 ,服务依然可以正常调用,但是现在相当于在访问 lb2 节点:
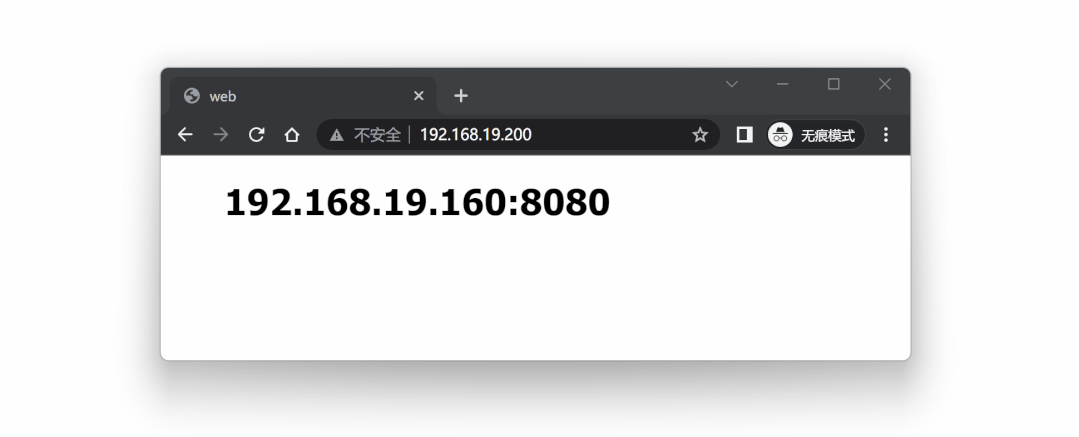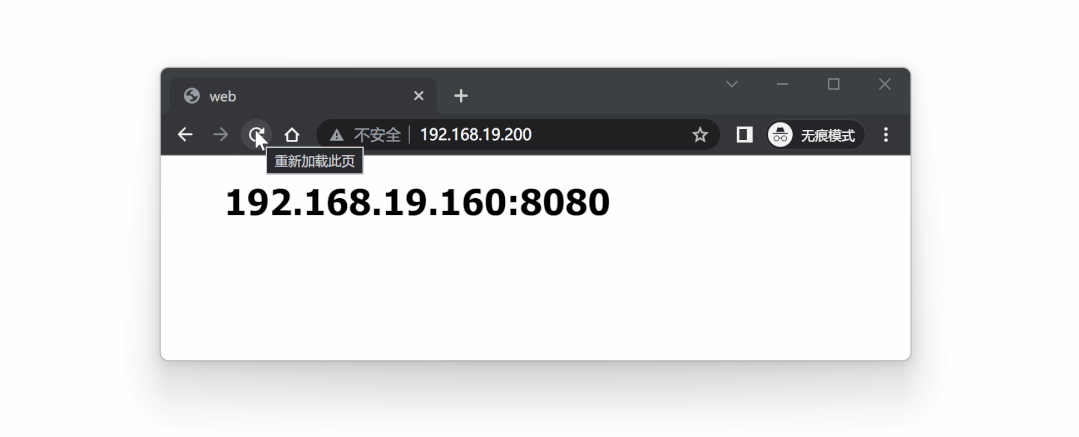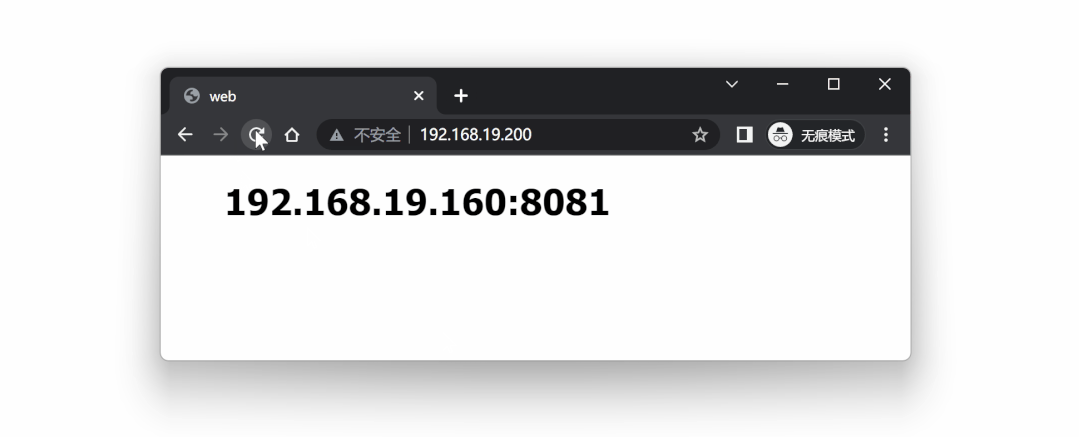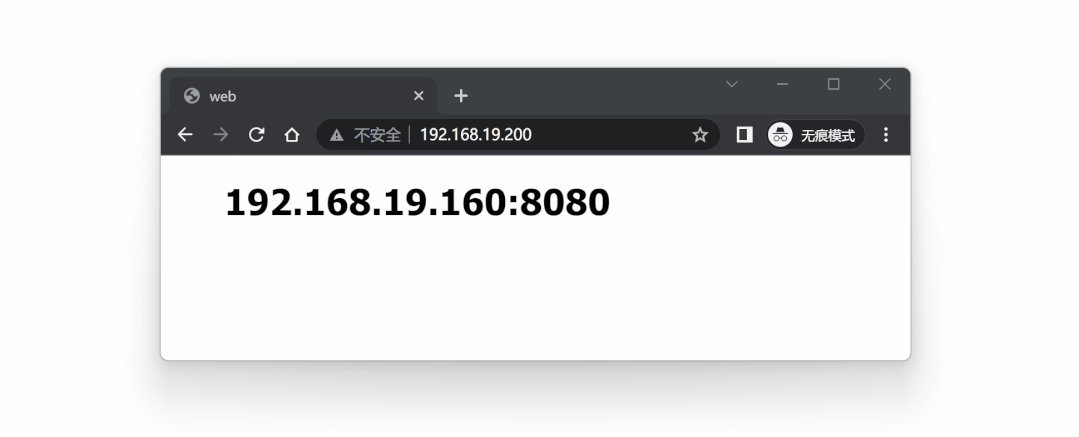
借助 keepalived ,我们成功实现了 nginx 代理的高可用,但是现在这种方案还是有缺陷的。
其实当前我们使用的是双机主备方式(Active-Standby 方式),即备用服务器在正常情况下一直处于闲置状态,这种方式不太经济实惠。
对于双机热备,其实就是双机高可用,还有另一种方案:双主机方式(Active-Active 方式),即两台服务器互为主备状态,任意一台故障后,另一台可以接管其流量。
双主机方式
我们还是利用 keepalived 来实现双主机方式。和之前的双机主备方式不同的是,现在需要两个 VIP 。
比如我们还是创建一个 VIP 为 192.168.19.200 ,正常情况下,该 VIP 绑定到 lb1 上;但是额外再创建一个 VIP 为 192.168.19.201 ,正常情况下,该 VIP 绑定到 lb2 上。
一旦 lb1 发生故障,VIP 192.168.19.200 立即漂移到 lb2 上;同样的,lb2 发生故障,VIP 192.168.19.201 则立即漂移到 lb1 上。
而对于外部访问端,我们可以适当分配,一部分客户端调用 192.168.19.200 这个 VIP ,另一部分调用 192.168.19.201 。lb1 和 lb2 任意一个发生故障,对于外部访问端都是可用状态。
修改 lb1 节点的 keepalived.conf :
! Configuration File for keepalived
global_defs {
# # 通知邮件服务器的配置
# notification_email {
# # 当 master 失去 VIP 的时候,会发一封通知邮件到 your-email@qq.com
# your-email@qq.com
# }
# # 发件人信息
# notification_email_from keepalived@qq.com
# # 邮件服务器地址
# smtp_server 127.0.0.1
# # 邮件服务器超时时间
# smtp_connect_timeout 30
# 唯一 id ,通常设置为 hostname
router_id lb1
}
# 检查nginx是否存活
vrrp_script check_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2 # 检测时间间隔
weight -20 # 检测失败(脚本返回非0)则权重 -20
}
# 定义虚拟路由,VI_1 为虚拟路由的自定义标识符
vrrp_instance VI_1 {
state MASTER # 主节点为 MASTER ,备份节点为 BACKUP
priority 100 # 节点优先级,MASTER 比 BACKUP 高
interface ens33 # 绑定虚拟 IP 的网络接口
virtual_router_id 101 # 虚拟路由的 id ,两个节点设置必须一样
advert_int 1 # 心跳报文发送间隔,默认 1s
# 默认组播模式下,keepalived 所有的信息都会向 224.0.0.18 的组播地址发送,产生众多的无用信息,并且可能会产生干扰和冲突
# 可以使用单播模式,这是一种安全的方法,避免局域网内有大量的 keepalived 造成虚拟路由 id 的冲突
unicast_src_ip 192.168.19.158 # 配置单播的源地址,本机 IP
unicast_peer {
192.168.19.159 # 配置单播的目标地址,其它 IP
}
# 设置验证信息,两个节点必须一致
authentication {
auth_type PASS
auth_pass 123456
}
track_script {
check_nginx # 执行 Nginx 监控的服务
}
# 虚拟 IP 池, 两个节点设置必须一样
virtual_ipaddress {
192.168.19.200 # 虚拟 ip,可以定义多个
}
}
vrrp_instance VI_2 {
state BACKUP
priority 50
interface ens33
virtual_router_id 102
advert_int 1
unicast_src_ip 192.168.19.158
unicast_peer {
192.168.19.159
}
authentication {
auth_type PASS
auth_pass 123456
}
track_script {
check_nginx
}
virtual_ipaddress {
192.168.19.201
}
}
lb2 节点的 keepalived.conf :
! Configuration File for keepalived
global_defs {
# # 通知邮件服务器的配置
# notification_email {
# # 当 master 失去 VIP 的时候,会发一封通知邮件到 your-email@qq.com
# your-email@qq.com
# }
# # 发件人信息
# notification_email_from keepalived@qq.com
# # 邮件服务器地址
# smtp_server 127.0.0.1
# # 邮件服务器超时时间
# smtp_connect_timeout 30
# 唯一 id ,通常设置为 hostname
router_id lb2
}
# 检查nginx是否存活
vrrp_script check_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2 # 检测时间间隔
weight -20 # 检测失败(脚本返回非0)则权重 -20
}
# 定义虚拟路由,VI_1 为虚拟路由的自定义标识符
vrrp_instance VI_1 {
state BACKUP # 主节点为 MASTER ,备份节点为 BACKUP
priority 50 # 节点优先级,MASTER 比 BACKUP 高
interface ens33 # 绑定虚拟 IP 的网络接口
virtual_router_id 101 # 虚拟路由的 id ,两个节点设置必须一样
advert_int 1 # 心跳报文发送间隔,默认 1s
# 默认组播模式下,keepalived 所有的信息都会向 224.0.0.18 的组播地址发送,产生众多的无用信息,并且可能会产生干扰和冲突
# 可以使用单播模式,这是一种安全的方法,避免局域网内有大量的 keepalived 造成虚拟路由 id 的冲突
unicast_src_ip 192.168.19.159 # 配置单播的源地址,本机 IP
unicast_peer {
192.168.19.158 # 配置单播的目标地址,其它 IP
}
# 设置验证信息,两个节点必须一致
authentication {
auth_type PASS
auth_pass 123456
}
track_script {
check_nginx # 执行 Nginx 监控的服务
}
# 虚拟 IP 池, 两个节点设置必须一样
virtual_ipaddress {
192.168.19.200 # 虚拟 ip,可以定义多个
}
}
vrrp_instance VI_2 {
state MASTER
priority 100
interface ens33
virtual_router_id 102
advert_int 1
unicast_src_ip 192.168.19.159
unicast_peer {
192.168.19.158
}
authentication {
auth_type PASS
auth_pass 123456
}
track_script {
check_nginx
}
virtual_ipaddress {
192.168.19.201
}
}
其实就是在之前的基础上增加了 VI_2 虚拟路由,创建 VIP 192.168.19.201 ,lb2 为主服务器,lb1 为备服务器。
重启 lb1 节点的 keepalived 服务:
[root@lb1 keepalived]# systemctl restart keepalived
[root@lb1 keepalived]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.19.158/24 brd 192.168.19.255 scope global noprefixroute dynamic ens33
inet 192.168.19.200/32 scope global ens33
[root@lb1 keepalived]#
lb2 节点的 keepalived 服务:
[root@lb2 keepalived]# systemctl restart keepalived
[root@lb2 keepalived]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.19.159/24 brd 192.168.19.255 scope global noprefixroute dynamic ens33
inet 192.168.19.201/32 scope global ens33
[root@lb2 keepalived]#
对两个 VIP 进行测试:
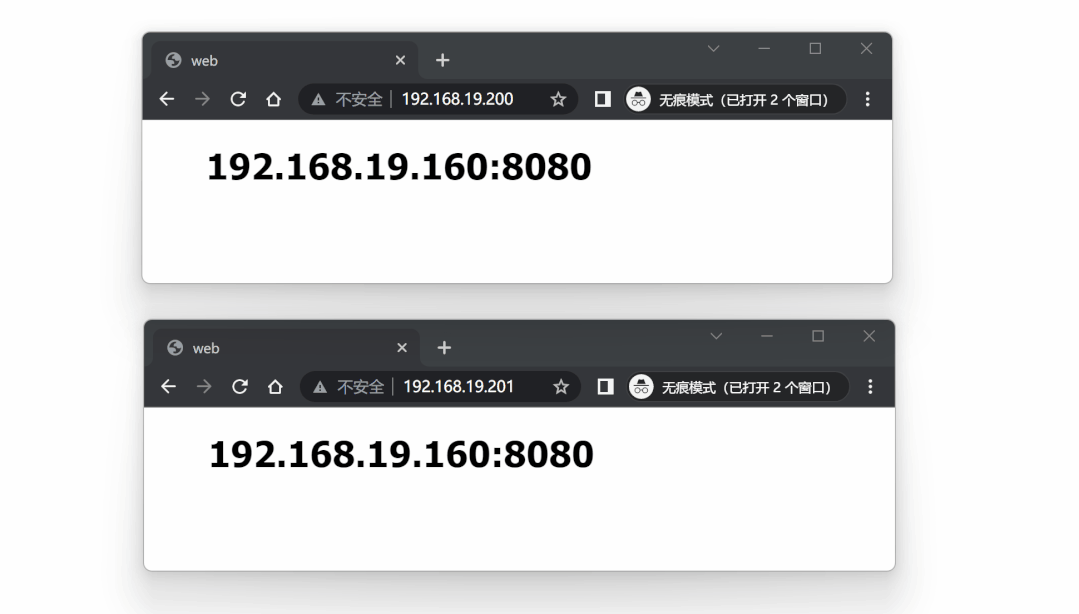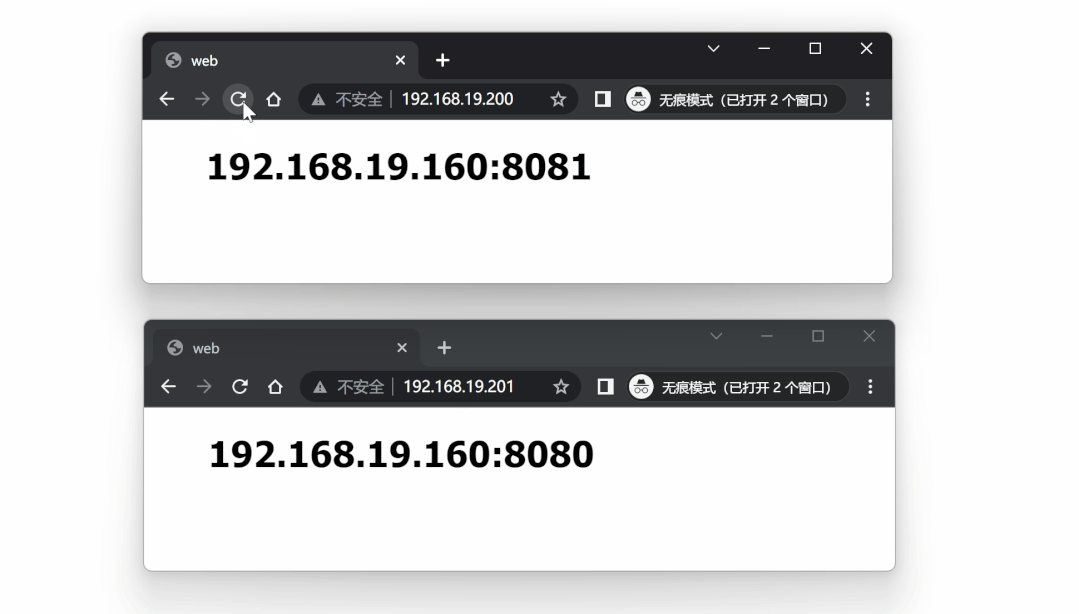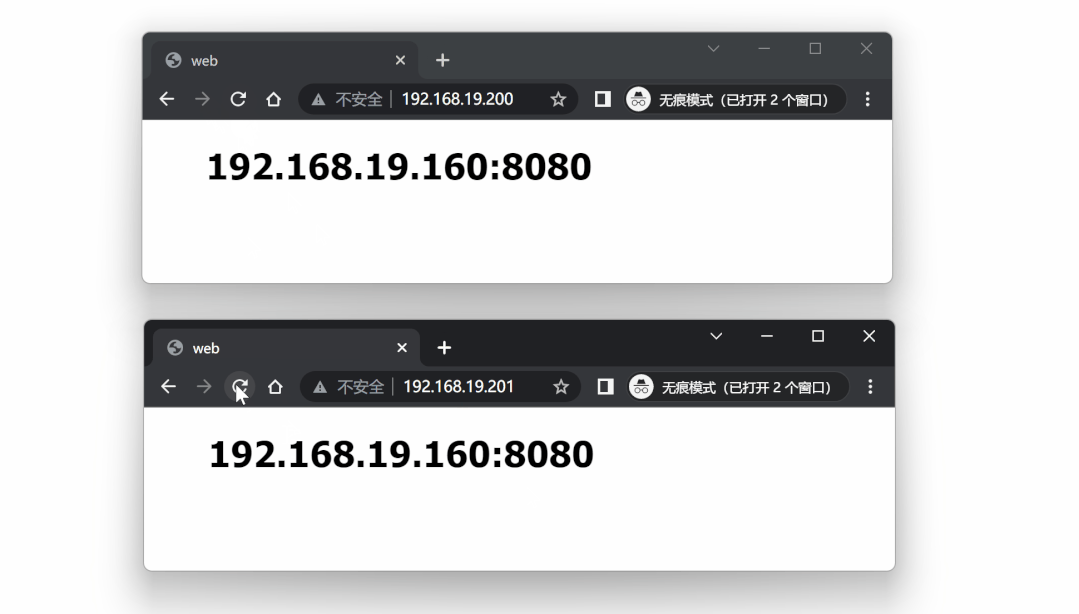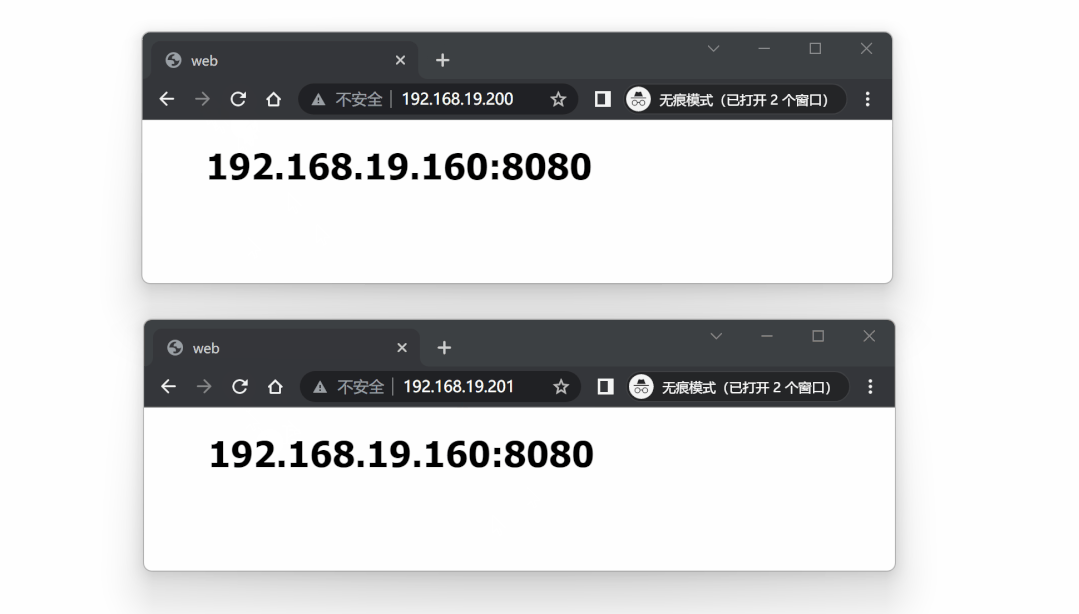
故障模拟,停止 lb2 节点的 nginx 代理服务:
[root@lb2 keepalived]# docker stop nginx
nginx
[root@lb2 keepalived]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.19.159/24 brd 192.168.19.255 scope global noprefixroute dynamic ens33
[root@lb2 keepalived]#
查看 lb1 IP 信息,发现 VIP 192.168.19.201 已漂移到 lb1 上:
[root@lb1 keepalived]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.19.158/24 brd 192.168.19.255 scope global noprefixroute dynamic ens33
inet 192.168.19.200/32 scope global ens33
inet 192.168.19.201/32 scope global ens33
[root@lb1 keepalived]#
再次对两个 VIP 进行测试,仍然处于可用状态:
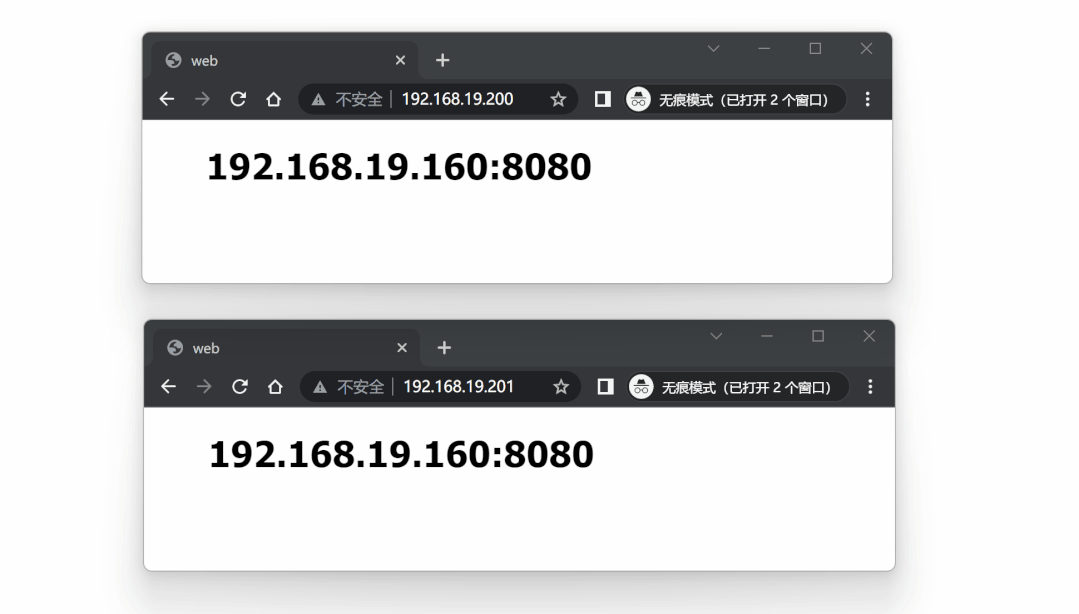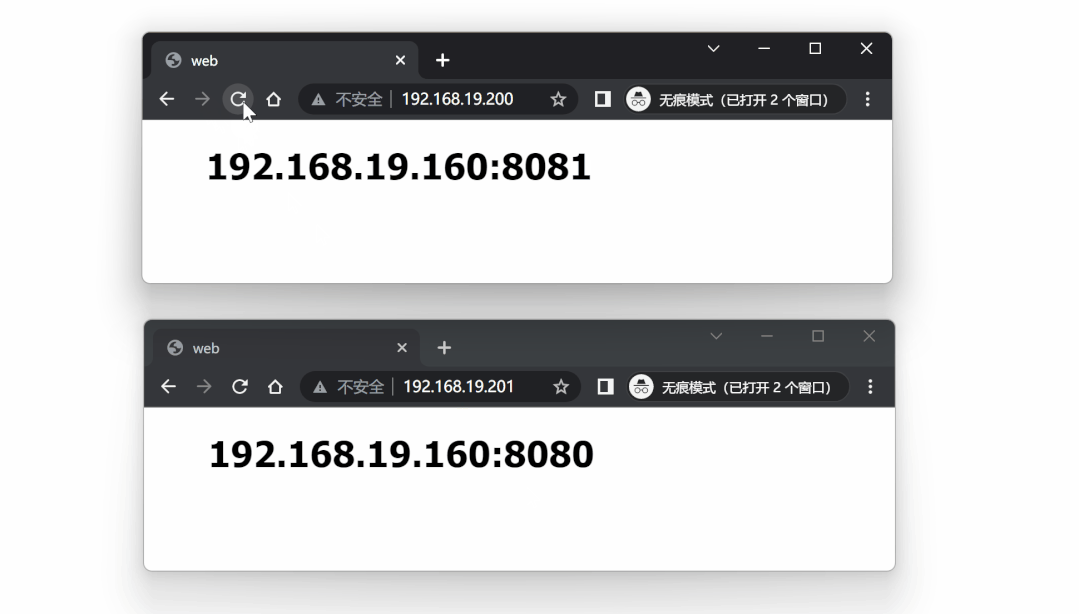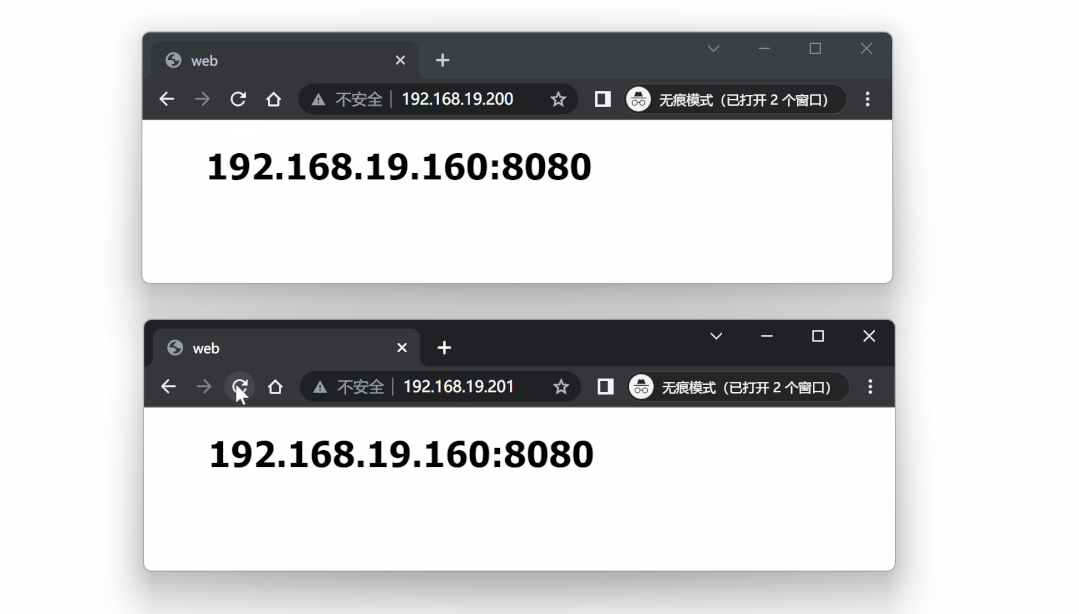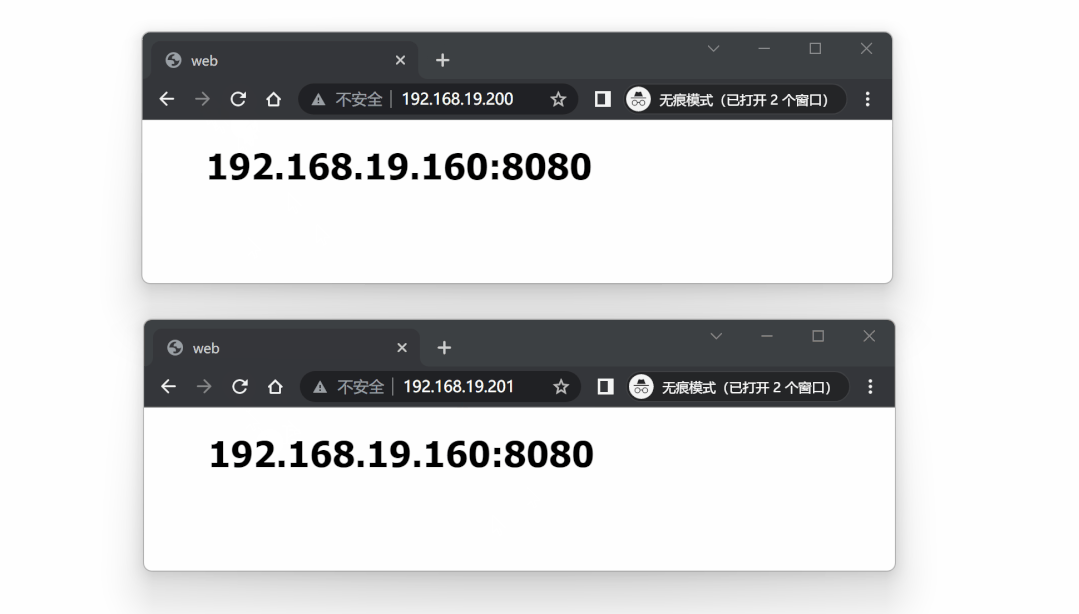
到此,我们也实现了基于双主机方式的高可用代理方案。
总结
高可用的核心就是做 “冗余” ,有了 “冗余” 后就得考虑做自动故障转移,使 “冗余” 的实例可以快速顶替使用。
本文介绍了 双机主备方式 和 双主机方式 两种方案来解决代理的高可用。但是软件开发没有银弹,因为这两种方案都是在一个局域网内进行的,还是有很大的不可控风险,如果再继续优化,就得考虑 同城双活 、异地双活 直至 异地多活 ,而这些就必须得靠强大的基础设施能力来支撑了。
 蜀ICP备20004578号
蜀ICP备20004578号