1 主数据系统的必要性
随着企业信息化的不断深入,企业建设的业务系统、办公系统等信息系统越来越多。由于规划、预算、实施计划等原因限制,各信息系统建设的步调不一致,规划不统一,导致一个严重的问题:一些基础数据,比如商品编码、客户编码等,在不同信息系统内取值不一致,甚至定义也不一致,为各业务系统打通,以及数据中心建设带来极大的障碍。这些基础数据一般称为主数据,对主数据的规范和梳理需要建设“主数据系统”。
主数据问题主要有几个方面:
各系统基础数据定义不一,集中的数据处理(比如 BI、大数据、机器学习等)需要经过繁琐的数据清洗、格式化、一致性检查和转换等步骤,代价巨大;
数据字典各自为政,甚至存在无法调和的逻辑矛盾,比如在 A 系统是主键的字段在 B 系统却允许不唯一;
有时候尽管定义了统一的规范,但各系统独立维护,也无法保证主数据的一致性。
由此,主数据系统的建设宜早不宜晚,特别是对于已经在使用 ERP 的传统企业。但是,由于主数据系统偏重于“技术优化”的范畴,很难在业务上见到立竿见影的效果,甚至对于业务人员都是“透明”的,而且还投入不小,所以对于如何申请到资源并立项,是个不小的挑战。但这不在本文讨论的范围内。
2 主数据系统设计的基本原则
主数据系统的设计方法很多,但大多数都需要对原有信息系统进行伤筋动骨的改动。因此,各企业在主数据系统的实施上都比较保守,宁愿花费大量的人工处理,以及诸多的各系统补丁,进行数据清理和转换,这种方案效率低而且无法解决根本性问题。
在结构上,由于多个应用系统之间,都可能存在提供数据和使用数据两种角色,一般采用点对点两两交互的网状结构,这种结构对同步时序、转换规则、系统复杂度等均提出了极高的要求,也带来——复杂性高,实施周期长,无法分步实施,容易失败等问题。
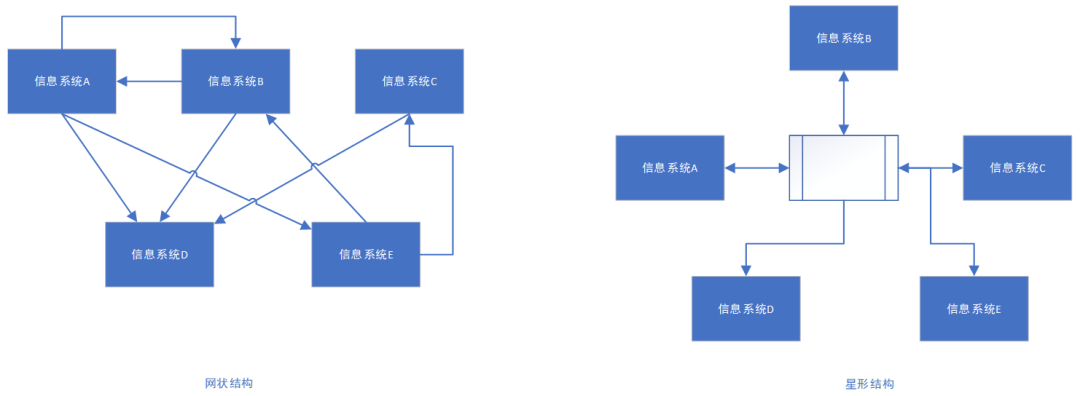
图 1 网状结构和星形结构
很显然,星形结构明显由于网状结构,而且必然对原信息系统的修改更少。
主数据系统设计原则几个要点如下:
- 数据同步从一般的“网状结构”改为稳定性高的“星形结构”,打破点对点两两交叉的复杂结构;
- 通过“数据代理”方式,不侵入原信息系统,不需要对原系统进行大量改动,可以进行有计划的分步实施;
- 主数据系统对每一条数据记录,设置全域范围唯一的 uuid 记录识别码,用于主数据记录全生命周期的识别、映射和转换;
- 所有数据转换、映射均由主数据系统实现,对原系统完全“透明”;
- 关联记录通过 uuid 多次映射的方式,确保任何现有系统以及将来接入的系统,都无需关心源数据的关联关系,复杂度大大降低。
3 主数据系统的具体实现
下面结合一种实现方法,给出完整的数据库设计和流程图。并对其中的关键点进行详细阐述。该项目已经上线运行半年多,可靠性和数据一致性均经过严格验证。
本项目几个前提如下:
(1)所有业务系统数据库都是 MySQL;
(2)所有业务系统数据提供者的主数据表都有 id 主键,但字段名不一定为“id”,也不一定具有自增属性;
(3)所有业务系统数据提供者的主数据表都有最后更新时间戳,同样字段名各不相同;
(4)所有业务系统数据提供者均以标志位标识“删除”,而不进行记录的物理删除。
3.1 总体架构
总体架构为星形结构,如图 2:
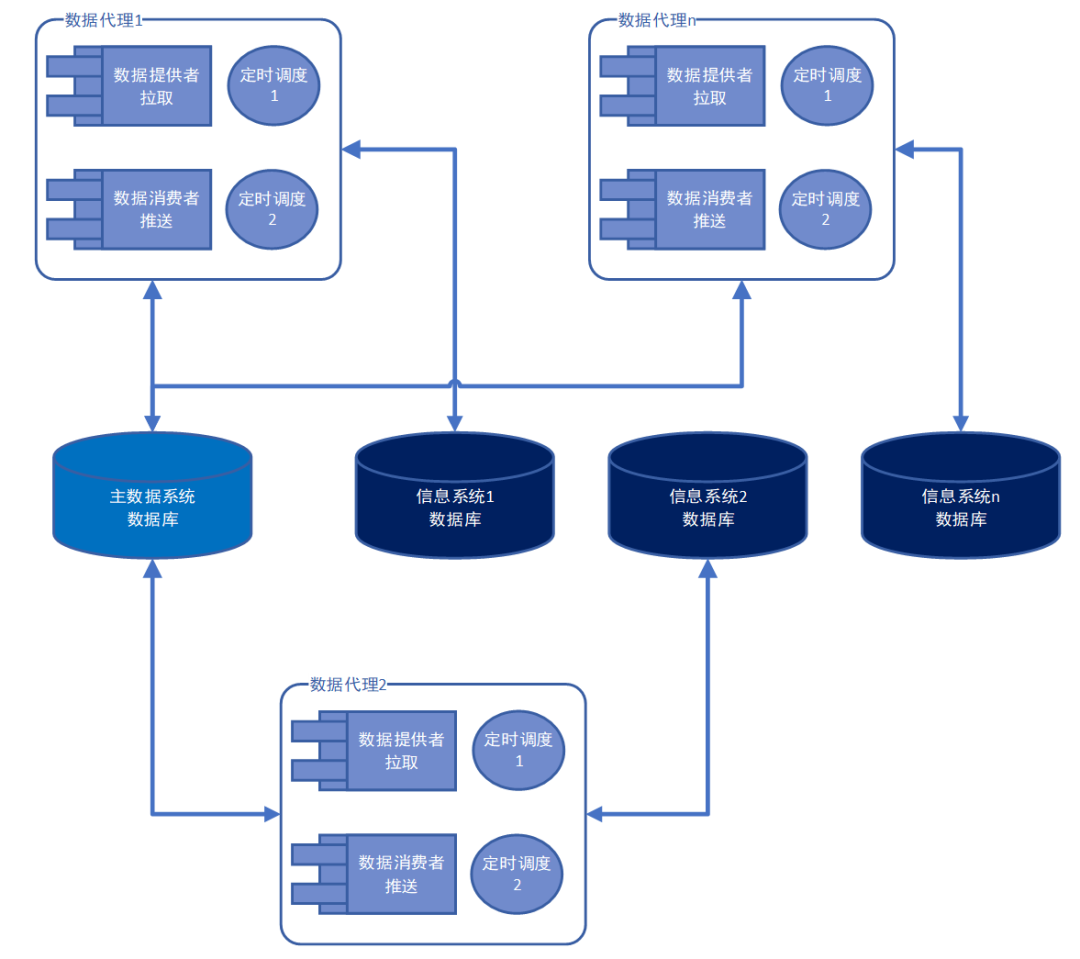
图 2 主数据系统总体架构图
其中:
(1)为简化设计,基于前提的第 2、3 点,数据代理直接采用数据库连接方式,定时对数据提供者的数据库表进行轮询。由此,对于数据提供者对应主数据表必须具有读权限,对于数据消费者的对应主数据表必须具有 insert/update 权限;
(2)数据代理(1~n),每个均连接主数据数据库和唯一一个信息系统数据库。业务系统数据库的“数据消费者”和“数据提供者”角色可能只有一种,例如,办公自动化(OA)系统,可能只作为“数据提供者”角色,提供组织架构、人员等主数据。这种情况下,该“数据代理”无需配置和调度“数据消费者”功能。
(3)MySQL 数据库表结构定义可以从 information_schema.COLUMNS 直接获取,其他数据库可以找类似系统表,如果没有,则需要单独填充字段定义。
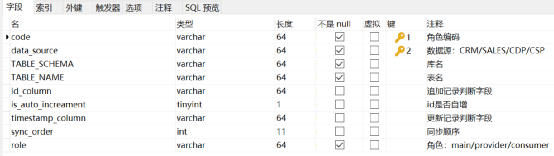
(4)数据库设计如下:
- tb_columns_def:表结构定义,从 information_schema.COLUMNS 直接复制
- tb_data_role:数据角色定义
3.2 数据提供者拉取
功能流程如图 3:
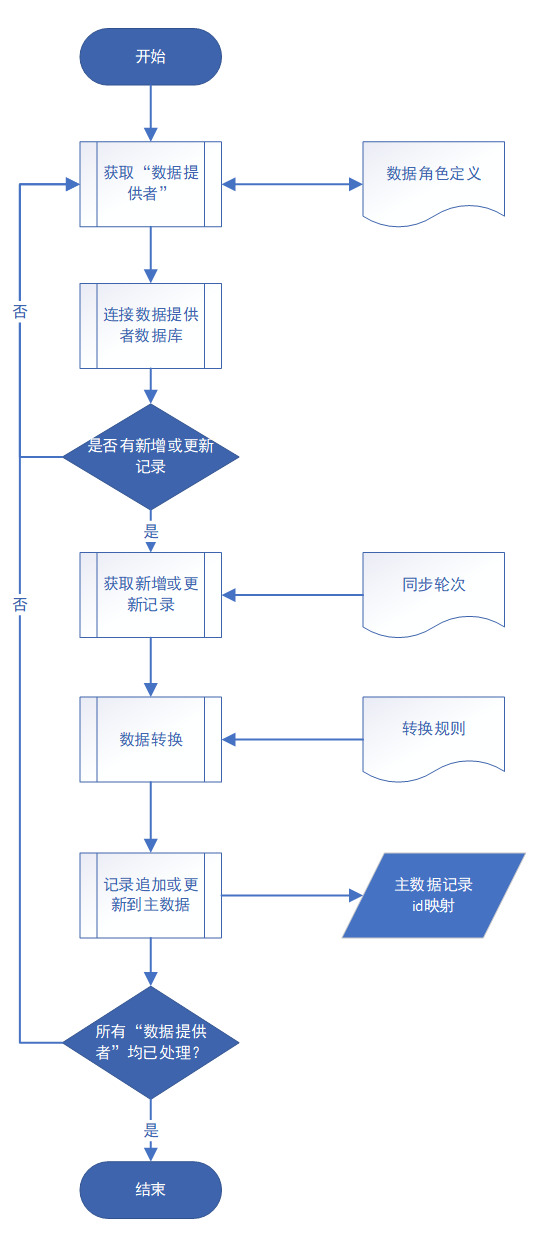
图 3“数据提供者”拉取流程
其中:
(1)被定时调度(本项目设置 1 分钟一次)激活后,连接对应的信息系统数据库,检查是否有新增或更新记录,如有,则进行数据拉取——从源数据数据库拉取并存入主数据数据库,同时记录“同步轮次”。
(2)一个信息系统可能提供多个“数据提供者”,在全部数据提供者都轮询并处理结束后,流程结束。
(3)数据库设计如下:
tb_data_sync_log:同步日志表,保存同步控制数据
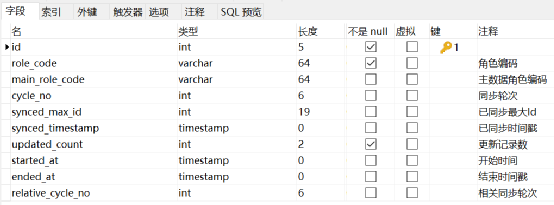
3.3 数据消费者推送
功能流程如图 4:
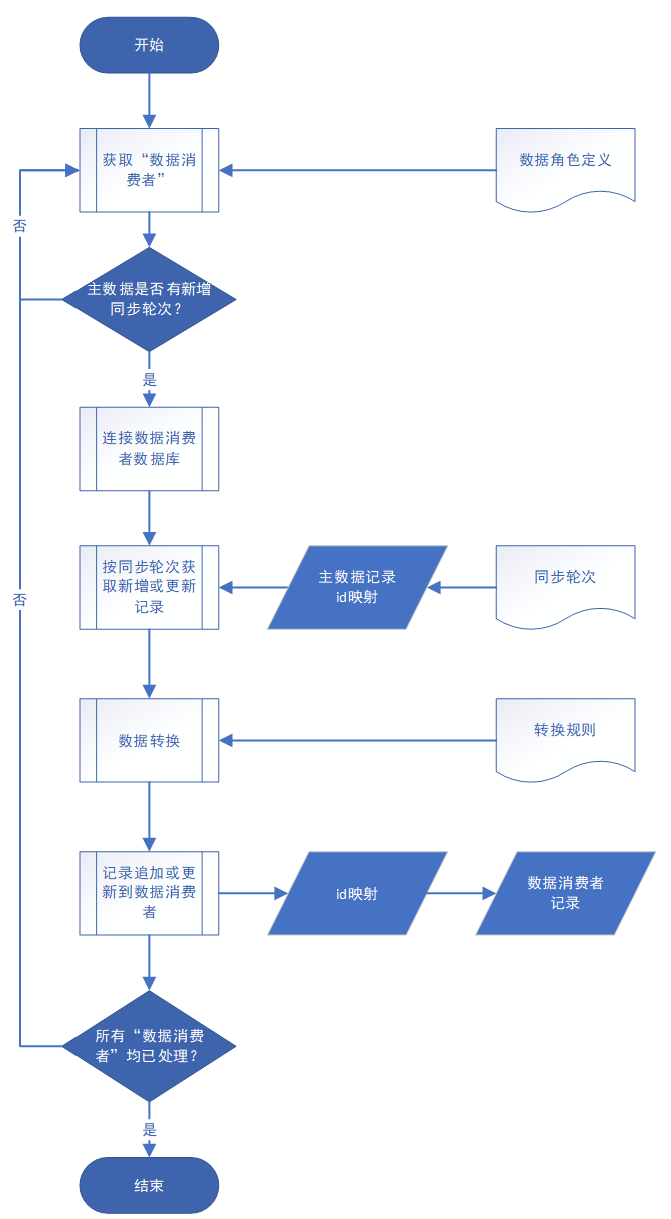
图 4 数据消费者推送流程
其中:
(1)被定时调度激活后,检查主数据系统“同步轮次”是否有新增,如有,则进行数据推送。连接数据消费者信息系统数据库,从主数据数据库推送新增或更新数据记录到信息系统数据库,同时记录“同步轮次”。
(2)检查主数据系统“同步轮次”是否有新增,通过 tb_data_sync_log.relative_cycle_no 与对应主数据(main_role)记录的最新伦次比较。
(3)一个信息系统可能需要多个“数据消费者”,在全部数据消费者都轮询并处理结束后,流程结束。
(4)数据库设计同数据提供者(参见第 2 节)。
3.4 数据转换
功能流程如图 5:
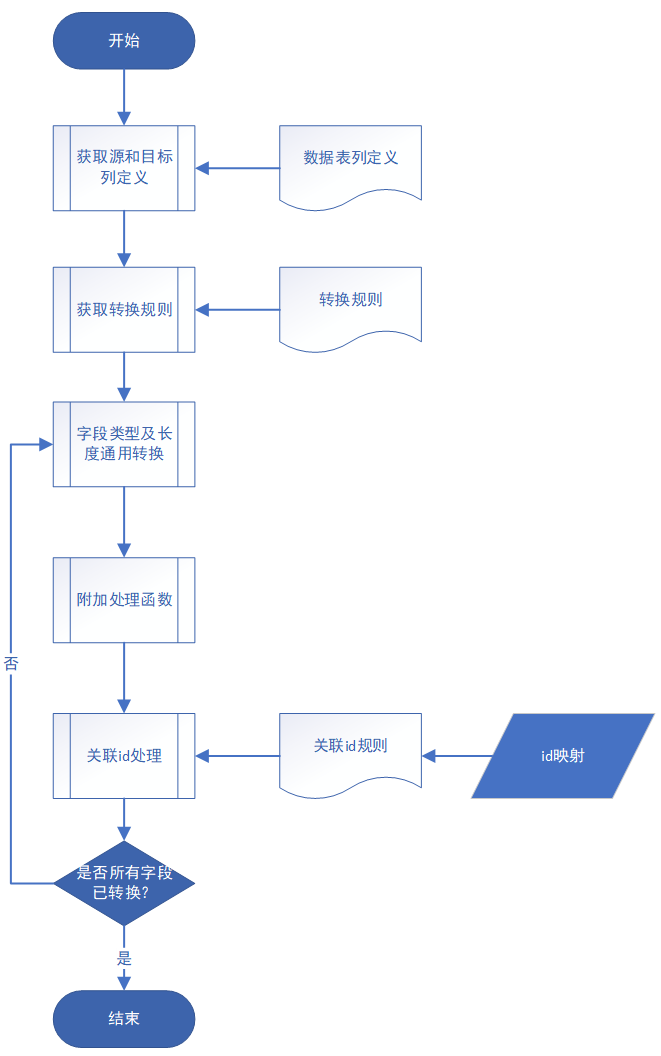
图 5 数据转换流程
其中:
(1)数据转换是不同信息系统与主数据之间,字段类型、长度、格式转换的核心模块。
(2)数据转换通过参数配置和附加处理函数,实现高度灵活性。
(3)数据转换首先获取源和目标数据表的字段定义,其次获取对应字段的转换规则。对所有已定义转换规则的字段进行处理:
A、对字段类型、长度进行通用转换;
B、调用附加处理函数(如果有),进行特殊转换;
C、按照关联 id 规则(如果有),读取主数据数据库的 id 映射,进行 对应关联 id 处理;
D、循环处理所有字段。
(4)数据库设计如下:
tb_transfer_def:转换规则定义表
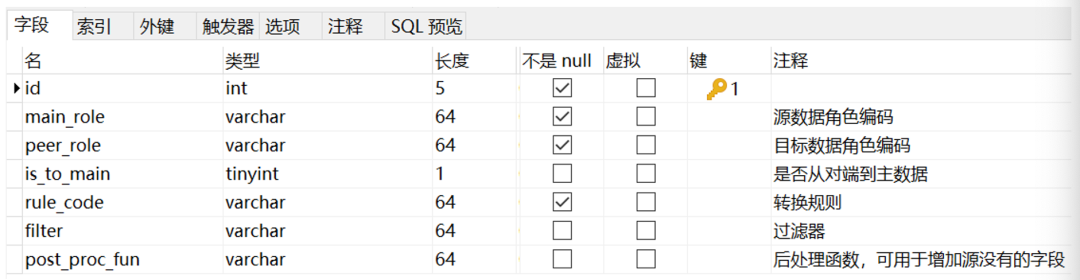
tb_transfer_rule:转换规则字段映射表
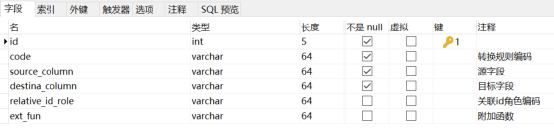
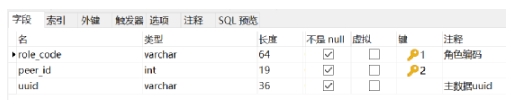
tb_id_mapping:id 映射表
4 关键点总结
主数据系统涉及多个系统的数据同步,由于各异构系统的差异性,导致主数据系统复杂度较高,成功的案例不多。本项目基于前述前提,取得较好的效果。现将关键点总结分享如下:
1、数据提供者的新增 id 和更新时间戳,对于不具备这两个条件的数据提供者,无法辨识新增和更新,不能进行增量同步,必须进行改造。如果由于种种原因源数据无法改造,则可以考虑变通方法,利用数据库自有同步工具(例如 Oracle 的 DGG 等),在同步的副本中增加新增和更新标识;
2、不管数据提供者还是数据消费者,无法进行数据库直接连接的,则“数据代理”需要以外挂应用的形式存在,与主数据系统的通讯采用 WebService 方式。将带来缓存、重试、幂等……多个复杂度的大大提高。
3、由于不同主数据表之间字段上存在映射关系,比如人员的所属部门的,需要在 id 映射上做多次转换,基本原则就是以落地主数据的 uuid 为“唯一权威”,其他关系都通过与 uuid 映射获得。
4、待补充——从数据库设计中,经过思考可以去发现,不再赘述。
 蜀ICP备20004578号
蜀ICP备20004578号